AI 真的能提升视频画质吗?

“AI 真的能提升视频画质吗?”这个问题的答案并不是简单的 yes/no。**现代 AI 并不是把丢失的像素“找回来”,而是用更好的像素把它们“替换掉”——通过智能重建来生成更可信的细节。**这个区别非常关键:它解释了为什么 AI 在某些场景下效果惊人,在另一些场景下却会翻车;也解释了为什么结果看起来很真实,但技术上依然属于“生成/幻觉出来的细节”。
这篇文章会深入讲清 AI 视频增强背后的原理:从传统放大与 AI 超分辨率的根本差异,到让现代工具真正可用的突破——时序一致性(temporal consistency)。我们还会聊 Topaz Video AI 这类本地工具与云端平台如何处理视频、为什么“增强视频”比“增强图片”难得多,以及一些现实基准(benchmark)能告诉你什么。
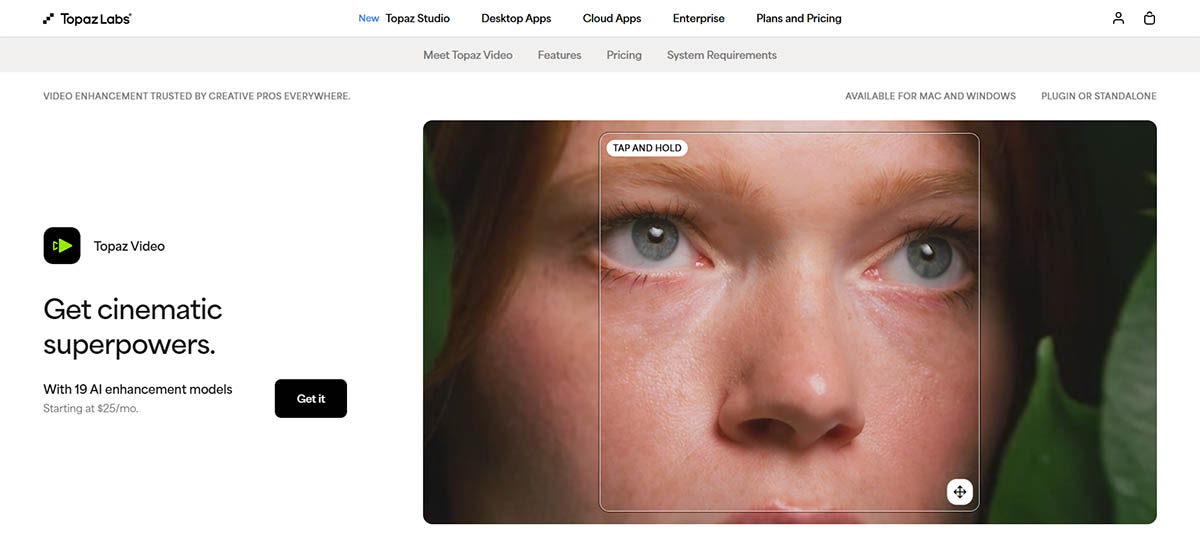
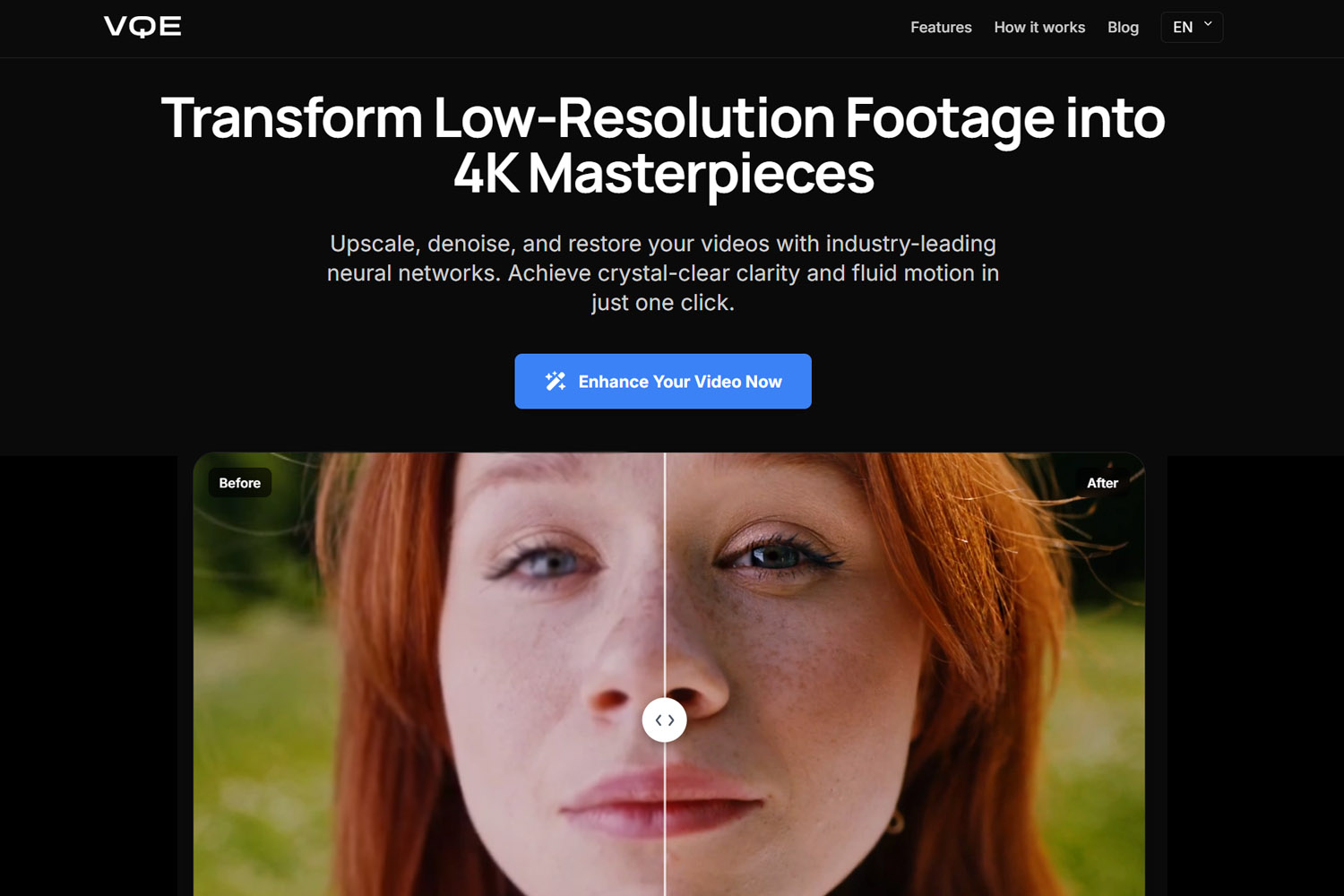
超越 CSI 的“Enhance!” 梗
犯罪剧里的“Enhance!”在 2005 年几乎是纯幻想,但到 2026 年已经“部分可实现”。**2005 年的插值算法只能拉伸现有像素,不能生成新细节。**当时缺少能在视觉上可信地重建缺失信息的技术。
现代 AI 完全改变了这个等式。**AI 不是恢复丢失像素,而是基于学到的视觉模式,用更合理的像素替换它们。**当你把低分辨率视频喂给 AI 增强器时,神经网络会识别模式(人脸、纹理、物体),并生成与高质量训练数据相匹配的“可信细节”。这不是“还原”,而是“智能重建”。
原始数据悖论
**视频增强的根本悖论是:提升意味着“可信重建”,而不是“真实恢复”。**如果视频是以 480p 录的,那么数据里并不存在一份“隐藏的 4K 版本”。相机从未捕捉到那种细节。传统放大方法承认这一点:它只会拉伸像素,让画面更大,但信息并不会变多。
AI 超分辨率的做法不同。**它不会拉伸像素,而是分析内容并生成看起来自然、可信的新细节。**它看到“这是脸”,就基于训练数据生成睫毛、皮肤纹理与面部结构。结果观感会好很多,但那是“重建的细节”,不是“找回的细节”。

理解这个区别有助于判断 AI 能做什么、不能做什么。**当源素材还保留足够信息、AI 能准确识别模式时,增强往往很有效;当源素材太糟糕,AI 缺少可用信息,就更容易出现伪影与不稳定。**这也是为什么在处理模糊视频去模糊或低分辨率视频放大时,先评估“可增强阈值”非常重要。
传统放大 vs AI 超分辨率
弄清这两者的区别,才能理解为什么现代工具效果明显更好,以及何时该用哪一种。
传统方法:双三次与 Lanczos 插值
双三次(bicubic)和 Lanczos 等传统放大方法有点像把橡皮筋拉长:越拉越薄。这些算法用数学公式去“猜”像素之间应该长什么样,把已有信息分摊到更多像素上。双三次插值用三次多项式估计像素值,Lanczos 采样用窗函数 sinc 获得更平滑结果。
流程很直观:1080p 想变 4K,算法就把每个像素“扩成”多个像素。**像素更多了,但信息没有新增。**因此画面更大却不一定更清晰:你只是在更大的画布上摊开同一份有限的信息。
小倍率(1.5×、2×)时还能看,但倍率更大就会露馅。到 4× 这种尺度,传统插值通常会变得软、糊,因为纯数学插值无法凭空生成可信细节。
AI 超分辨率:用“模糊草图”重绘
AI 超分辨率更像是根据一张模糊草图重画一张细节丰富的画。**它不会拉伸像素,而是分析模式与纹理,生成与内容类型匹配的新细节。**神经网络会判断它看到的是人脸/建筑/自然场景,然后按训练数据生成更像“高分辨率版本”的细节。

**核心差别:AI 超分辨率依赖“学到的视觉模式”,而不是纯数学插值。**处理低清人脸时,它不会把像素拉开;它会识别面部结构,并生成睫毛、皮肤毛孔等细节,让结果更自然。
这种方式的结果通常比传统插值更像“真实高清”。AI 生成的细节会跟内容类型一致(纹理、边缘、细小结构),对人眼更可信。它不一定“真实”,但通常更“好看、好用”。
“超分辨率”这个术语
**Super-resolution(超分辨率)是 AI 提升分辨率的技术名称。**它指的是用 AI 在原传感器未捕捉到的分辨率上生成可信细节,而不是简单拉伸像素。这也是现代 AI 增强与传统放大的本质分界。
2026 年的 AI 视频增强工具到底怎么工作
2026 年的 AI 视频增强不是单一算法。Topaz Video AI 与 Video Quality Enhancer 这类工具,实际上是多个系统组合协作,分别优化画质的不同维度。理解这些模块就能明白为什么现代工具比早期版本好用得多。
空间增强:提升分辨率(Upscaling)
空间增强会把 720p/1080p 放大到 1080p/4K。AI 会重建缺失细节,而不是拉伸像素:通过识别纹理与结构,生成更合理的高分辨率信息。
它会按内容类型生成细节:**人脸会得到面部细节与皮肤纹理;建筑会得到结构与材质细节。**在 2×~4× 的倍率里,AI 通常信息还够用,预测更可靠;超过 4× 时可靠性下降,更容易出现不真实的细节与伪影。
时域增强:运动与补帧(Frame Interpolation)
时域增强通过生成中间帧,把 24fps 转成 60fps 或做慢动作。AI 通过运动模式生成中间帧,并尽量保持自然运动。
原理是理解物体如何移动:AI 分析帧间运动向量,预测“中间那一帧”应当是什么样,从而让运动更顺滑。对走路、开车、镜头平移等规律运动效果最好;场景过于复杂、遮挡多、运动模糊重时更容易出问题,但好的实现仍能得到很可信的结果。
智能去噪:区分颗粒与噪声
智能去噪要分清“好纹理”(胶片颗粒)与“坏噪声”(数字噪点/压缩噪声)。AI 会跨多帧分析,判断哪些是噪声、哪些是真细节,从而选择性地去除噪声并保留纹理。

噪声往往是随机的、帧与帧之间变化大;真实细节更稳定且有模式。通过多帧对比,AI 能更准确地删噪而不“磨皮成塑料”。现代去噪还会在合适时保留颗粒质感,避免过度平滑。
人脸修复与细化(Face Recovery)
人脸修复会用专门的人脸模型增强脸部,同时保持自然。这些模型会稳定眼睛、皮肤纹理与表情,减少“蜡像皮肤”问题。

专业工具之所以要人脸专用模型,是因为人类对脸极度敏感。脸看起来不对,整个视频都会显得假,哪怕背景已经很清晰。没有人脸模型,你可能会得到“背景 4K、脸还是糊”的违和结果。
图片 AI vs 视频 AI:为什么视频更难
视频增强比图片增强难得多,因为视频必须保证时序一致性:细节不仅要在单帧好看,还要在连续播放中稳定。
为什么逐帧增强会失败
把每一帧独立处理会带来典型灾难:纹理闪烁、细节爬动、人脸漂移,播放时非常明显。
原因是逐帧处理不考虑上下文:某个纹理在这一帧被增强成一种形态,下一帧又变了,就会出现“闪”。眼睛/皮肤纹理在帧间漂移也会让人很出戏。这些问题往往比原本的低清更刺眼,导致“越增强越糟”。
真正的突破:时序一致性(Temporal Consistency)
现代工具通过多帧联合分析解决这个问题。时序一致性算法会把当前帧与前后多帧一起看,借助邻近帧信息来维持稳定。
**细节必须在时间上稳定,而不仅是单帧漂亮。**这也是为什么 Topaz 与云端平台会投入大量精力在时域分析上:增强的是整段序列,而不是一张张图片的堆叠。
扩散模型(Diffusion)简明解释
扩散模型是近几年 AI 视频增强的重要进展,尤其在细节生成上往往强于早期 GAN。
扩散模型到底是什么?
**扩散模型是一类生成模型,通过迭代细化来预测可信的视觉细节。**训练过程通常是学习“去噪”的逆过程:从带噪输入逐步还原出更清晰、更细节的图像。
它们在纹理、人脸、细小结构生成上很强,因为训练数据规模大且质量高。模型学到如何生成符合自然外观的细节,因此对人眼很有说服力。
Stable Diffusion:原生是图像模型,不是视频模型
Stable Diffusion 是图像模型,不是原生视频模型,所以直接用于视频会遇到时序一致性问题。实践中常见做法是逐帧扩散 + 额外的时域引导来减少闪烁。
这能用,但不完美:逐帧扩散容易在帧间产生不一致,必须靠额外机制“锁住”细节。
2026 前沿:混合管线(Hybrid Pipeline)
更先进的工具会把传统超分辨率作为“稳定底座”,再用扩散做“细节精修”。这种混合方式融合了稳定性(传统方法)与细节能力(扩散),相比早期纯 GAN 更自然、更稳。
AI 过度时的“假感”问题
AI 增强如果太激进,或源素材太差,就容易变假。
常见翻车形态
伪影(artifacting):AI 误读纹理,生成不该有的结构(比如莫名其妙的砖纹、错误布料纹理)。
蜡像皮肤(waxy skin):过度平滑抹掉真实皮肤纹理,像塑料。
过度锐化(over-sharpen):边缘像“画上去”的,质感不自然,进入“恐怖谷”。
现代解法:可控强度 + 颗粒保真
专业工具会提供强度控制、纹理保留、以及颗粒保留/回注(grain re-injection)。合适的增强强度往往比“拉满”更好看。
现实基准:不同素材大概能到什么程度
了解工具在不同来源上的上限,能帮助你设定期望。
低质量来源:VHS / MiniDV / 480p
低质量来源的“主观提升”往往很明显:能从 480p 拉到 1080p/4K,变得更清晰、更干净、更可看。
但要记住:**结果依然会保留年代感,不会变成真正的现代 4K。**AI 不能抹掉一切源限制,只能把它变得更易看。
如果源素材压缩太重或运动模糊严重,提升会打折扣。处理模糊片段时,先判断模糊类型会更靠谱。
中等质量来源:1080p 手机/相机
**中等质量来源更容易达到“接近原生 4K”的观感。**这正是 Topaz 与云端平台最强的甜点区间:源素材信息够多,AI 的预测更准确,生成的细节更自然。
关键仍在于码率:高码率 1080p 往往比低码率 1080p 更容易放大得好看,因为保留的信息更多。
指标 vs 人眼:为什么“看起来更好”很重要
AI 增强后的画面可能在某些技术指标(如 VMAF)上更差,但人眼却觉得更好看。这揭示了“感知质量”与“像素忠实度”的矛盾。
精确度悖论
AI 增强可能让 VMAF 变低,因为 AI 生成了原视频不存在的细节;而很多指标衡量的是“对源的忠实度”。VMAF 由 Netflix 提出,确实与人眼相关,但它仍然偏向衡量与源的一致性。
**但人眼更在乎清晰度、脸部质量与运动稳定性。**因此你会看到“指标下降、观感上升”的情况。
为什么会这样?
**AI 追求的是观感,不是逐像素复刻。**它被优化为“让人觉得更清晰、更自然”,而不是“和原图一模一样”。如果你不确定素材是否适合增强,可以让工具或工作流先做诊断与试跑;你也可以参考这篇:ChatGPT 能帮你分析并指导放大吗?。
如何判断一个视频增强工具是否真的好
很多评测只看单帧或放大截图,但忽略了影响视频观感的关键测试。
大多数评测没做的测试
**时序闪烁测试:**纹理是否在播放中“闪”。
**人脸稳定测试:**眼睛/皮肤是否在帧间漂移。
**运动完整性测试:**快速运动时是否出现扭曲/变形。
更“专业”的洞察
**参考帧分析:**高级工具会从邻近更清晰的帧“借细节”来修复当前帧。
**避免过熟:**轻度、克制的增强往往比“拉满重建”更自然。
**硬件现实:**本地工具吃 GPU,云端工具降低门槛。若你在 ChatGPT 的帮助下制定工作流,见:ChatGPT 如何参与视频增强流程。
最终结论:AI 真的能提升视频画质吗?
可以,但要带着正确的理解与期待。
AI 不是恢复“真实”
**AI 不是恢复丢失的真实,而是重建可信的细节。**480p 里没有隐藏的 4K。AI 输出的是它认为“应该在那里的东西”,这叫重建,不叫恢复。
做对了会更稳、更自然、观感更好
**当工具具备时序一致性、并且强度设定得当时,结果通常稳定、自然且观感明显更好。**关键是选对工具、匹配素材,并且避免过度处理。
AI 视频增强不是关于“真相”,而是关于“可信的清晰”
**AI 视频增强的目标不是“还原真相”,而是“看起来更清晰、更可信”。**只要增强后的画面更干净、更稳定、更自然,它就达成了目的——即使细节在技术上属于“生成”。
带着这个视角,你就能更合理地评估结果:AI 适合在素材还保留足够信息时做可信重建;在素材过度劣化时,它更容易产生不稳定与伪影。理解阈值、选择合适工具与强度,才是获得高质量结果的关键。