AI có thực sự cải thiện chất lượng video được không?

Câu hỏi “AI có thật sự cải thiện chất lượng video không?” có câu trả lời phức tạp hơn một chữ “có/không”. AI hiện đại không khôi phục lại các pixel đã mất. Thay vào đó, nó thay thế chúng bằng các pixel tốt hơn thông qua quá trình tái dựng thông minh. Phân biệt này quan trọng vì nó giải thích vì sao AI nâng video hoạt động rất “ảo” trong một số trường hợp nhưng lại thất bại ở trường hợp khác — và vì sao kết quả trông thuyết phục dù về mặt kỹ thuật là chi tiết “hallucinated”.
Bài này sẽ đi sâu vào “khoa học” phía sau AI video enhancement: từ khác biệt nền tảng giữa upscaling truyền thống và AI super-resolution, đến bước đột phá về temporal consistency khiến các công cụ hiện đại trở nên khả dụng. Chúng ta cũng sẽ xem cách các tool như Topaz Video AI và nền tảng cloud xử lý video, vì sao nâng video khó hơn nâng ảnh, và các benchmark nói gì về kết quả thực tế.
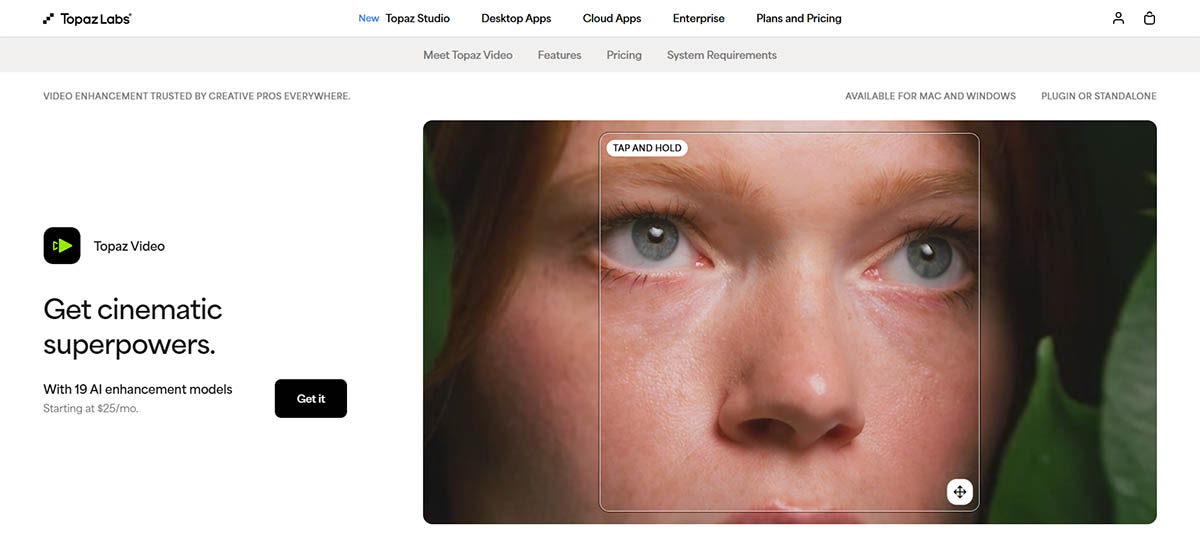
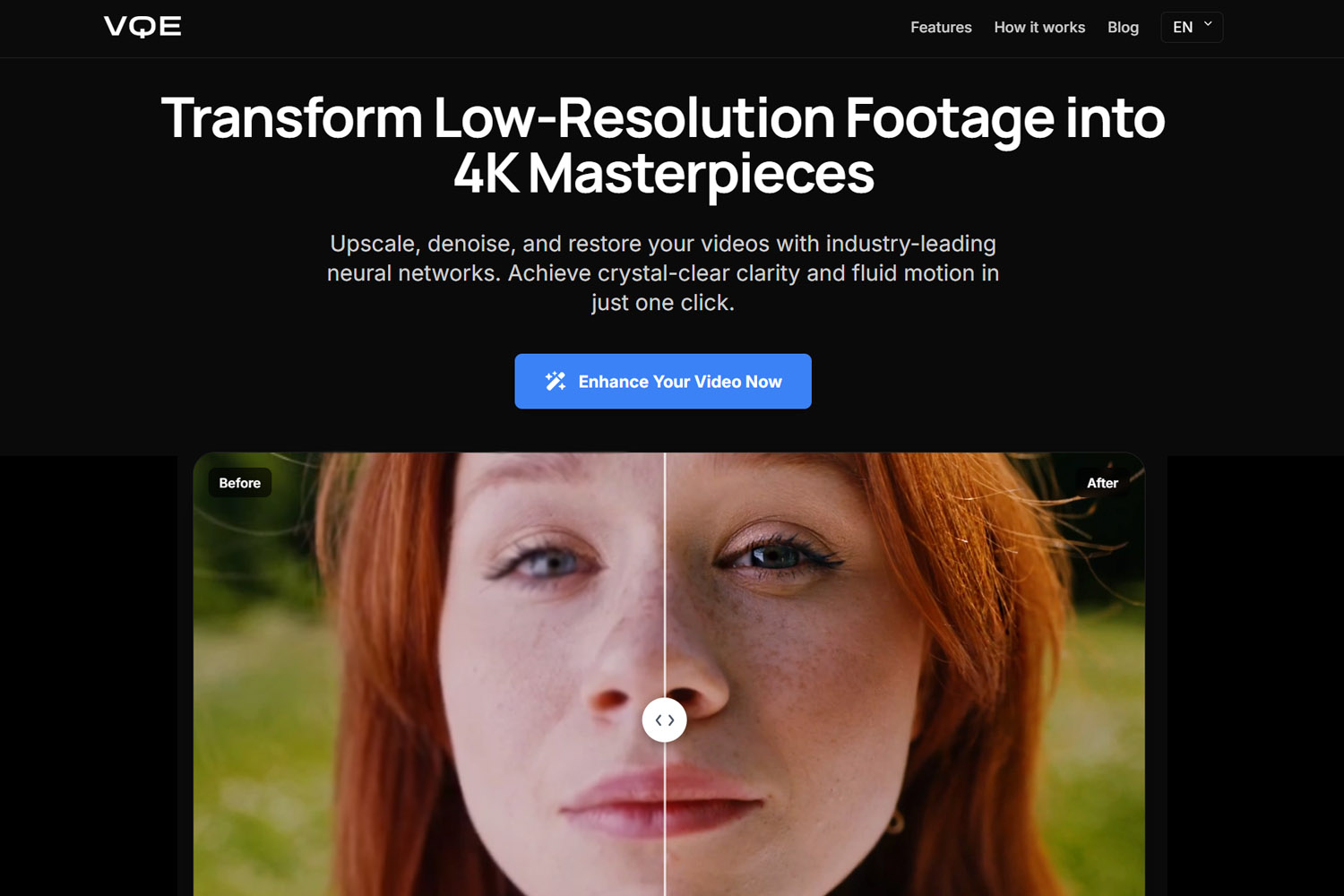
Vượt qua meme “Enhance!” kiểu CSI
Meme “Enhance!” trong phim trinh thám là một tưởng tượng bất khả thi của năm 2005 — và đến 2026 thì cuối cùng cũng phần nào làm được. Năm 2005, nội suy toán học chỉ có thể kéo dãn pixel hiện có. Nó không thể tạo chi tiết mới. Công nghệ khi đó chưa đủ để tái dựng thông tin bị thiếu một cách thuyết phục.
AI hiện đại thay đổi cuộc chơi. AI không “lấy lại” pixel đã mất. Nó thay thế chúng bằng các pixel tốt hơn dựa trên pattern thị giác mà nó đã học. Khi bạn đưa một video độ phân giải thấp vào tool AI, mạng nơ-ron nhận ra pattern (khuôn mặt, texture, vật thể) và tạo chi tiết hợp lý dựa trên dữ liệu huấn luyện chất lượng cao. Đây không phải phục hồi (restoration). Đây là tái dựng thông minh (intelligent reconstruction).
Nghịch lý dữ liệu gốc
Nghịch lý cốt lõi của nâng video: cải thiện nghĩa là tái dựng hợp lý, không phải phục hồi sự thật. Nếu video được quay ở 480p, không có “bản 4K” nào đang ẩn trong dữ liệu. Camera chưa từng ghi lại chi tiết đó. Upscaling truyền thống thừa nhận giới hạn này bằng cách chỉ kéo dãn pixel, tạo ảnh lớn hơn nhưng không có thông tin mới.
AI super-resolution làm khác. Thay vì kéo dãn pixel, AI phân tích nội dung và tạo chi tiết mới trông tự nhiên và thuyết phục. AI nhận ra “đây là một khuôn mặt” và tạo lông mi, texture da, đường nét gương mặt dựa trên cách khuôn mặt trông như thế nào trong dữ liệu huấn luyện độ phân giải cao. Kết quả nhìn tốt hơn rõ rệt, nhưng đó là chi tiết được tái dựng, không phải chi tiết “lấy lại” từ footage gốc.

Phân biệt này giúp bạn hiểu AI làm được gì và không làm được gì. AI mạnh khi footage gốc còn đủ thông tin để nhận dạng pattern chính xác, giúp mạng nơ-ron đưa ra dự đoán có cơ sở. Khi footage quá xuống cấp, AI không đủ thông tin để “đoán”, dẫn đến artifact và kết quả thiếu ổn định. Hiểu “ngưỡng” này giúp bạn quyết định có nên nâng hay không — dù bạn đang xử lý video bị mờ cần deblur hay video độ phân giải thấp cần upscale.
Upscaling truyền thống vs AI super-resolution
Hiểu khác nhau giữa upscaling truyền thống và AI super-resolution sẽ giải thích vì sao các tool hiện đại cho kết quả tốt hơn hẳn, và khi nào mỗi cách hợp lý.
Phương pháp truyền thống: nội suy bicubic và Lanczos
Upscaling truyền thống như bicubic và Lanczos giống như kéo dãn dây thun đến khi nó mỏng ra. Các thuật toán này dùng công thức toán để “đoán” pixel ở giữa các điểm đã biết, tạo ảnh lớn hơn bằng cách phân bổ thông tin hiện có lên nhiều pixel hơn. Thuật toán bicubic interpolation dùng đa thức bậc ba để ước lượng giá trị pixel, còn Lanczos resampling dùng hàm sinc có cửa sổ để cho kết quả mượt.
Cách làm khá thẳng: nếu bạn có ảnh 1080p muốn lên 4K, thuật toán sẽ tạo bốn pixel từ mỗi pixel gốc bằng nội suy toán học. Nhiều pixel hơn, nhưng không có thông tin mới. Ảnh lớn hơn nhưng không nhất thiết sắc hơn vì bạn đang trải cùng một lượng thông tin ít ỏi lên một khung lớn hơn.
Cách này ổn với hệ số upscale nhỏ (1.5× hoặc 2×), nhưng sẽ tệ khi scale lớn. Ở mức 4×, phương pháp truyền thống thường ra kết quả mềm, mờ vì nguồn không đủ thông tin để tạo chi tiết thuyết phục chỉ bằng nội suy.
AI super-resolution: vẽ lại từ một bản phác mờ
AI super-resolution giống như vẽ lại một bức tranh chi tiết từ bản phác mờ. Thay vì kéo dãn pixel, AI phân tích pattern và texture để tạo chi tiết mới phù hợp loại nội dung. Mạng nơ-ron nhận ra nó đang nhìn gì (mặt người, tòa nhà, cảnh tự nhiên) và tạo chi tiết hợp lý dựa trên dữ liệu huấn luyện.

Khác biệt cốt lõi: AI super-resolution dựa trên pattern thị giác đã học, không phải nội suy toán học. Khi xử lý một khuôn mặt độ phân giải thấp, AI không chỉ kéo pixel. Nó nhận ra cấu trúc mặt và tạo lông mi, lỗ chân lông, chi tiết nhỏ dựa trên dữ liệu huấn luyện độ phân giải cao.
Cách này cho kết quả tự nhiên hơn upscaling truyền thống. AI tạo chi tiết phù hợp với loại nội dung, dựng texture/edge/chi tiết nhỏ trông thuyết phục với mắt người. Chi tiết đó không “thật” theo nghĩa được lấy từ footage gốc, nhưng nó hợp lý và đẹp hơn về mặt thị giác.
“Super-resolution” là thuật ngữ kỹ thuật
Super-resolution là thuật ngữ kỹ thuật cho nâng độ phân giải dựa trên AI. Nó mô tả quá trình tăng độ phân giải vượt quá mức cảm biến gốc ghi lại, bằng cách tạo chi tiết hợp lý thay vì chỉ kéo dãn pixel. Đây là điểm phân biệt AI enhancement hiện đại với upscaling truyền thống.
Tool AI nâng video hiện đại hoạt động như thế nào?
AI video enhancement năm 2026 không phải chỉ là một thuật toán. Các tool như Topaz Video AI và Video Quality Enhancer kết hợp nhiều hệ thống chuyên biệt để cải thiện các khía cạnh khác nhau của chất lượng video. Hiểu các thành phần này giúp giải thích vì sao tool hiện đại tốt hơn thế hệ cũ.
Nâng “không gian” (spatial): upscale độ phân giải
Nâng “spatial” tăng độ phân giải từ mức thấp (720p, 1080p) lên mức cao hơn (1080p, 4K). AI tái dựng chi tiết bị thiếu thay vì kéo dãn pixel, phân tích pattern/texture để tạo thông tin độ phân giải cao hợp lý.
Quá trình này dựa trên nhận dạng loại nội dung và tạo chi tiết tương ứng. Mặt người sẽ được tạo chi tiết mặt và texture da. Tòa nhà sẽ được tạo chi tiết kiến trúc và cấu trúc. AI dùng dữ liệu huấn luyện để dự đoán “phiên bản độ phân giải cao sẽ trông ra sao”, tạo kết quả tự nhiên và thuyết phục.
Cách này hoạt động tốt nhất với hệ số 2× đến 4×, nơi AI vẫn còn đủ thông tin nguồn để dự đoán chính xác. Vượt quá 4×, kết quả thường kém ổn định hơn vì AI thiếu dữ liệu để “đoán”, dẫn đến artifact và chi tiết phi thực.
Nâng “thời gian” (temporal): chuyển động và nội suy khung hình
Nâng “temporal” giúp chuyển động mượt hơn bằng cách tạo frame trung gian: đổi video 24fps lên 60fps hoặc tạo slow-motion. AI tạo frame trung gian nhưng vẫn giữ chuyển động tự nhiên, phân tích pattern chuyển động để tạo “in-between frame” hợp lý.
Điều này hoạt động nhờ hiểu vật thể di chuyển trong không gian. AI phân tích motion vector giữa các frame và dự đoán frame trung gian nên trông thế nào, tạo chuyển động mượt và tự nhiên hơn so với nội suy “cơ học”. Kết quả là playback “trơn” hơn, giảm cảm giác giật của video fps thấp.
Nội suy frame hiệu quả nhất với chuyển động đơn giản, dễ dự đoán như đi bộ, xe chạy, lia máy. Cảnh phức tạp nhiều vật thể chồng lấp hoặc motion blur nhanh có thể tạo artifact, nhưng nếu làm tốt, nâng temporal cho ra kết quả rất thuyết phục.
Khử nhiễu thông minh: tách grain và noise
Khử nhiễu thông minh phân biệt film grain (texture “đẹp”) và digital noise (artifact “xấu”), giữ texture tự nhiên nhưng loại bỏ nhiễu không mong muốn. AI phân tích pattern qua nhiều frame để xác định đâu là noise và đâu là chi tiết thật, cho phép loại bỏ có chọn lọc.

Điều này hiệu quả vì noise có đặc điểm: ngẫu nhiên, thay đổi theo frame, xuất hiện như hạt hoặc chấm màu. Chi tiết thật thì nhất quán và có pattern, giúp AI phân biệt hai thứ. Bằng cách phân tích nhiều frame, AI có thể bỏ noise mà vẫn giữ texture, cạnh và chi tiết quan trọng.
Kết quả là footage sạch hơn nhưng vẫn tự nhiên, tránh cảm giác “nhựa” và bị làm mịn quá tay của các phương pháp denoise truyền thống. Denoise AI hiện đại có thể giữ grain khi phù hợp, đồng thời giảm sensor noise và artifact do nén.
Phục hồi và tinh chỉnh khuôn mặt
Face recovery dùng model chuyên biệt được huấn luyện theo cấu trúc khuôn mặt để làm rõ mặt nhưng vẫn tự nhiên. Các model này giữ ổn định mắt, texture da và biểu cảm, tránh vấn đề “da sáp” mà upscaler tổng quát hay gặp.

Tool “pro” dùng model riêng cho mặt vì con người cực kỳ nhạy với khuôn mặt. Nếu mặt trông sai, cả video sẽ thấy “cấn”, dù nền có đẹp đến đâu. Model face recovery hiểu giải phẫu mặt và tạo chi tiết giống đặc điểm người thật, giữ vẻ tự nhiên xuyên suốt quá trình nâng.
Điều này đặc biệt quan trọng khi video có người, nhất là phỏng vấn, chân dung hoặc cảnh mặt nổi bật. Nếu không có face recovery chuyên biệt, nền có thể trông 4K nhưng mặt vẫn mờ, tạo sự lệch lạc khiến video trông tệ hơn bản gốc.
AI cho ảnh vs AI cho video: vì sao video khó hơn nhiều
Nâng video phức tạp hơn nâng ảnh vì video cần temporal consistency. Chi tiết phải ổn định qua thời gian, không chỉ đẹp ở một frame tĩnh.
Vì sao nâng từng frame riêng lẻ thường thất bại
Xử lý mỗi frame độc lập gây ra nhiều vấn đề khiến video trông tệ hơn. Nâng độc lập từng frame tạo texture nhấp nháy, chi tiết “bò” (crawling) và mặt không ổn định — rất dễ thấy khi xem playback.
Vấn đề là xử lý độc lập không dùng ngữ cảnh. Texture có thể nét ở frame này nhưng khác ở frame kế, tạo hiệu ứng “lấp lánh” khó chịu. Khuôn mặt có thể thay đổi giữa frame: mắt/da dịch chuyển theo cách sai.
Các artifact này đôi khi còn dễ thấy hơn chất lượng kém ban đầu, khiến nâng từng frame phản tác dụng. Video có thể “tăng độ phân giải”, nhưng sự bất nhất theo thời gian làm trải nghiệm tệ đi.
Đột phá thật sự: temporal consistency
Tool hiện đại giải quyết bằng cách phân tích nhiều frame cùng lúc để giữ chi tiết ổn định. Thuật toán temporal consistency phân tích frame hiện tại cùng một số frame trước và sau, dùng thông tin xung quanh để duy trì ổn định.
Chi tiết phải ổn định theo thời gian, không chỉ đẹp khi đứng hình. Đây là lý do các tool nghiêm túc như Topaz Video AI và nền tảng cloud như Video Quality Enhancer đầu tư mạnh vào phân tích temporal. Quá trình enhancement xét cả chuỗi, không chỉ frame đơn lẻ.
Nhờ “temporal awareness”, AI tránh nhấp nháy/crawling/mất ổn định. Texture nhất quán, khuôn mặt ổn định và chuyển động tự nhiên vì AI dùng thông tin từ nhiều frame để giữ coherence. Kết quả là video đẹp cả khi chụp màn hình lẫn khi xem chuyển động.
Giải thích diffusion model
Diffusion model là một bước tiến lớn trong AI video enhancement, thường tạo chi tiết tốt hơn so với hệ GAN đời trước.
Diffusion model thực chất là gì?
Diffusion model là mô hình sinh (generative) được huấn luyện để dự đoán chi tiết thị giác hợp lý thông qua quá trình tinh chỉnh lặp. Nó học cách “đảo ngược” quá trình thêm nhiễu, dần dần xây chi tiết từ đầu vào mờ hoặc nhiễu.
Những model này rất mạnh ở việc tạo texture, khuôn mặt và cấu trúc nhỏ vì được huấn luyện trên tập dữ liệu lớn ảnh/video chất lượng cao. Quá trình huấn luyện giúp model nhận ra pattern và tạo chi tiết trông tự nhiên, khiến kết quả thuyết phục với mắt người.
Stable Diffusion: model ảnh, không phải model video “native”
Stable Diffusion là model ảnh, không phải model video native, nên khi áp vào video sẽ có thách thức. Khi dùng cho video, diffusion thường được áp frame-by-frame rồi kết hợp thêm hướng dẫn temporal để giảm nhấp nháy.
Cách lai này dùng được nhưng không tối ưu. Diffusion frame-by-frame có thể tạo bất nhất theo thời gian, nên cần xử lý thêm để giữ ổn định giữa frame. Temporal guidance giúp, nhưng vẫn là “chữa cháy” cho model không sinh ra để làm video.
“Đỉnh” năm 2026: pipeline lai
Các tool tiên tiến 2026 dùng pipeline lai kết hợp super-resolution kiểu “cổ điển” với diffusion để refine chi tiết. Cách này vượt qua hệ GAN-only đời cũ, tận dụng điểm mạnh của cả hai.
Pipeline lai thường làm như sau: dùng super-resolution cổ điển để tạo nền tảng ổn định, rồi dùng diffusion để refine chi tiết. Kết quả vừa ổn định (nhờ phương pháp cổ điển), vừa giàu chi tiết (nhờ diffusion), tạo enhancement tự nhiên và thuyết phục.
Khi AI “quá tay”: vấn đề “trông giả”
AI enhancement có thể tạo artifact làm video trông giả, nhất là khi xử lý quá mạnh hoặc khi nguồn quá kém.
Các kiểu thất bại phổ biến
Artifact xuất hiện khi AI hiểu sai pattern, tạo chi tiết không khớp nội dung. Ví dụ “mọc” gạch ở nơi không có, texture vải bị tạo sai, hoặc pattern trông vô lý.
Da sáp xảy ra khi AI làm mất lỗ chân lông và texture, khiến mặt trông như nhựa. Điều này xảy ra khi thuật toán làm mịn quá mạnh, loại bỏ những biến thiên nhỏ giúp da trông thật.
Over-sharpening tạo chi tiết như bị “vẽ lên”, cạnh quá gắt và texture trông giả. Chi tiết có thể “đúng” về mặt kỹ thuật, nhưng không khớp cảm giác tự nhiên, tạo hiệu ứng uncanny valley.
Giải pháp hiện đại: kiểm soát mức nâng
Tool “pro” giải quyết bằng cách cho kiểm soát cường độ nâng và giữ grain. Bạn có thể điều chỉnh mức xử lý, tìm điểm cân bằng giữa cải thiện và tự nhiên.
Giữ grain (hoặc bù grain lại) giúp giữ texture tự nhiên vốn có thể bị mất khi xử lý. Một số tool phân tích và giữ grain gốc, hoặc thêm grain tổng hợp sau khi nâng để giữ “feel” tự nhiên.
Tool chuyên nghiệp thường cho phép tinh chỉnh để tránh over-processing, giúp bạn tối ưu cho kết quả tự nhiên thay vì “giả”.
Benchmark thực tế: các tool làm được đến đâu?
Hiểu tool thực tế làm được gì giúp bạn đặt kỳ vọng đúng và chọn đúng cách cho footage.
Nguồn chất lượng thấp: VHS, MiniDV, 480p
Nguồn chất lượng thấp thường cải thiện “cảm nhận” rất rõ khi dùng AI hiện đại. Băng VHS, MiniDV và video 480p có thể upscale lên 1080p hoặc 4K và trông tốt hơn hẳn bản gốc.
Nhưng kết quả vẫn có tính “stylized”, không biến thành footage hiện đại bằng phép màu. Footage sau nâng thường giữ “chất” của bản gốc nhưng sắc và sạch hơn. AI không thể xóa mọi giới hạn của nguồn, nhưng có thể làm nó dễ xem hơn đáng kể.
Cách này tốt nhất khi nguồn ít artifact do nén và còn tương đối nét. Footage bị nén nặng hoặc motion blur nhiều sẽ cải thiện kém hơn, nhưng ngay cả vậy tool hiện đại vẫn có thể giúp thấy rõ cải thiện. Khi xử lý video bị mờ, hiểu loại blur giúp bạn biết khả năng cứu được đến đâu.
Nguồn chất lượng trung bình: smartphone 1080p, DSLR
Nguồn chất lượng trung bình có thể đạt cảm giác 4K gần như native khi nâng bằng tool “pro”. Video smartphone/DSLR quay 1080p có thể upscale lên 4K và trông gần giống footage 4K gốc.
Đây là nơi các tool như Topaz Video AI và Video Quality Enhancer tỏa sáng nhất. Nguồn còn đủ thông tin để AI dự đoán chính xác, tạo chi tiết tự nhiên và thuyết phục. Footage giữ “chất” ban đầu nhưng đạt độ phân giải/cảm nhận chất lượng cao hơn.
Điểm then chốt là nguồn ban đầu phải “đàng hoàng”. Video 1080p quay bitrate cao upscale sẽ tốt hơn video 1080p bitrate thấp, vì bitrate cao giữ nhiều thông tin hơn cho AI.
Metric vs mắt người: vì sao “trông đẹp hơn” mới quan trọng
Video được AI nâng có thể bị điểm kỹ thuật (như VMAF) thấp hơn, dù mắt người thấy đẹp hơn nhiều. Nghịch lý này cho thấy vì sao chất lượng “cảm nhận” quan trọng hơn độ chính xác từng pixel.
Nghịch lý “accuracy”
Video AI-enhanced có thể bị điểm VMAF thấp hơn vì quá trình nâng tạo chi tiết vốn không có trong nguồn. Metric kỹ thuật đo độ trung thực so với nguồn, trong khi AI enhancement cố tình tạo chi tiết mới — khiến điểm “fidelity” giảm. Metric VMAF của Netflix kết hợp nhiều phép đo để dự đoán cảm nhận của người xem, nhưng nó vẫn đo mức giống nguồn nhiều hơn là mức “cải thiện cảm nhận”.
Trong khi đó, người xem lại thấy video đẹp hơn rõ rệt, vì họ quan tâm độ rõ, khuôn mặt và độ ổn định chuyển động hơn là việc từng pixel có khớp nguồn hay không. Vì vậy metric có thể nói “tệ hơn” nhưng mắt người lại thấy “đẹp hơn”.
Vì sao lại vậy?
AI ưu tiên chất lượng cảm nhận, không ưu tiên độ chính xác từng pixel. Nó được tối ưu để trông đẹp với mắt người, không phải để khớp nguồn pixel-by-pixel. Vì vậy AI có thể tạo chi tiết làm tăng cảm nhận chất lượng dù làm giảm độ chính xác kỹ thuật.
Con người quan tâm độ rõ, khuôn mặt và chuyển động ổn định hơn là pixel có khớp nguồn. Nếu khuôn mặt sắc và tự nhiên hơn, người xem sẽ thấy chất lượng cao hơn, kể cả khi bản nâng không giống từng pixel. Nếu bạn không chắc footage có phù hợp nâng hay không, ChatGPT có thể giúp bạn phân tích chất lượng và gợi ý hướng xử lý.
Vì vậy, metric là một góc nhìn, còn cảm nhận người xem là góc nhìn khác — và với nâng video, cảm nhận thường là thứ bạn quan tâm nhất.
Làm sao biết một tool nâng video thật sự tốt?
Nhiều bài review chỉ nhìn “một frame đẹp” mà bỏ qua các yếu tố quyết định việc nâng có thật sự cải thiện video hay chỉ tạo vấn đề mới.
Những bài test mà nhiều review bỏ qua
Test nhấp nháy theo thời gian: texture có “lấp lánh” giữa các frame không? Tool tốt giữ texture ổn định; tool kém tạo flicker dễ thấy khi xem.
Test độ ổn định khuôn mặt: mắt và da có nhất quán giữa các frame không? Mặt nên ổn định và tự nhiên, không “đổi mặt” giữa frame.
Test chuyển động nhanh: có bị méo (warping) khi chuyển động nhanh không? Video nâng tốt phải giữ chuyển động tự nhiên, tránh méo và artifact khi action nhanh.
Insight kiểu “pro”
Phân tích reference frame cho thấy AI “mượn” chi tiết từ frame nét gần đó như thế nào. Tool nâng cao phân tích nhiều frame để tìm phiên bản nét nhất của từng chi tiết, rồi dùng thông tin đó để nâng các frame khác. Cách này chính xác hơn xử lý từng frame độc lập.
Tránh “nấu quá tay”: nâng vừa phải thường đẹp hơn nâng quá mạnh. Kết quả tốt nhất thường đến từ enhancement mức vừa đủ: cải thiện nhưng không tạo artifact. Xử lý quá mạnh có thể tạo nhiều chi tiết hơn, nhưng thường trông giả và làm tổng thể tệ đi.
Thực tế phần cứng: tool local cần GPU mạnh, còn cloud thì bỏ rào cản này. Topaz Video AI thường cần NVIDIA RTX hoặc Apple Silicon để chạy nhanh; cloud như Video Quality Enhancer không cần phần cứng mạnh. Nếu bạn đang dùng ChatGPT để hỗ trợ workflow, nó có thể giúp bạn chọn giữa local và cloud dựa trên cấu hình của bạn.
Kết luận cuối: AI có thật sự cải thiện chất lượng video không?
Câu trả lời là: có — nhưng kèm những lưu ý quan trọng để hiểu khi nào hiệu quả và khi nào không.
AI không “khôi phục lại sự thật đã mất”
AI không khôi phục lại sự thật đã mất. Nó tái dựng chi tiết trông hợp lý. Video quay 480p không có bản 4K ẩn trong dữ liệu. AI tạo chi tiết hợp lý dựa trên dữ liệu huấn luyện, không phải “đào lại” thông tin gốc.
Điều này quan trọng vì nó giúp bạn hiểu giới hạn. Video sau nâng là thứ AI “nghĩ” nên có, không chắc là thứ camera đã ghi. Đây là tái dựng, không phải phục hồi.
Nếu làm đúng, kết quả ổn định, tự nhiên và đẹp hơn
Khi làm đúng, AI enhancement cho kết quả ổn định, tự nhiên và đẹp hơn về mặt thị giác. Tool hiện đại có temporal consistency tạo video đẹp cả khi đứng hình lẫn khi xem chuyển động, giữ vẻ tự nhiên xuyên suốt.
Chìa khóa là dùng đúng tool cho nguồn và chọn mức enhancement phù hợp. Tool “pro” có phân tích temporal tốt sẽ cho kết quả thuyết phục và tự nhiên, tránh các artifact và bất ổn thường gặp khi xử lý frame-by-frame.
Nâng video bằng AI không phải “sự thật”: mục tiêu là độ rõ thuyết phục
AI video enhancement không phải về sự thật. Nó là về độ rõ thuyết phục. Mục tiêu không phải khôi phục thông tin đã mất, mà là tạo kết quả trông đẹp hơn với mắt người. Nếu video sau nâng sắc hơn, sạch hơn và tự nhiên hơn, nó đã đạt mục tiêu — dù chi tiết về mặt kỹ thuật là “hallucinated”.
Góc nhìn này giúp bạn đặt kỳ vọng đúng. AI tạo kết quả hợp lý và đẹp hơn về cảm nhận, không phải tái tạo hoàn hảo những gì đã mất. Công nghệ hoạt động tốt nhất khi nguồn còn đủ thông tin để nhận dạng pattern, giúp AI tạo chi tiết trông tự nhiên và thuyết phục.