Czy AI naprawdę może poprawić jakość wideo?

Pytanie "Czy AI naprawdę może poprawić jakość wideo?" ma złożoną odpowiedź, która wykracza poza proste tak lub nie. Nowoczesne AI nie przywraca utraconych pikseli. Zamiast tego zastępuje je lepszymi poprzez inteligentną rekonstrukcję. To rozróżnienie ma znaczenie, ponieważ wyjaśnia, dlaczego poprawa AI działa pięknie w niektórych scenariuszach, a w innych zawodzi, i dlaczego rezultaty wyglądają przekonująco, mimo że technicznie są "zhalucynowanymi" detalami.
Ten artykuł bada naukę stojącą za poprawą jakości wideo przez AI, od fundamentalnej różnicy między tradycyjnym skalowaniem a super-rozdzielczością AI po przełom spójności czasowej, który czyni nowoczesne narzędzia wykonalnymi. Zbadamy, jak narzędzia takie jak Topaz Video AI i platformy chmurowe przetwarzają wideo, dlaczego poprawa wideo jest trudniejsza niż poprawa obrazów i co benchmarki ujawniają o rzeczywistych rezultatach.
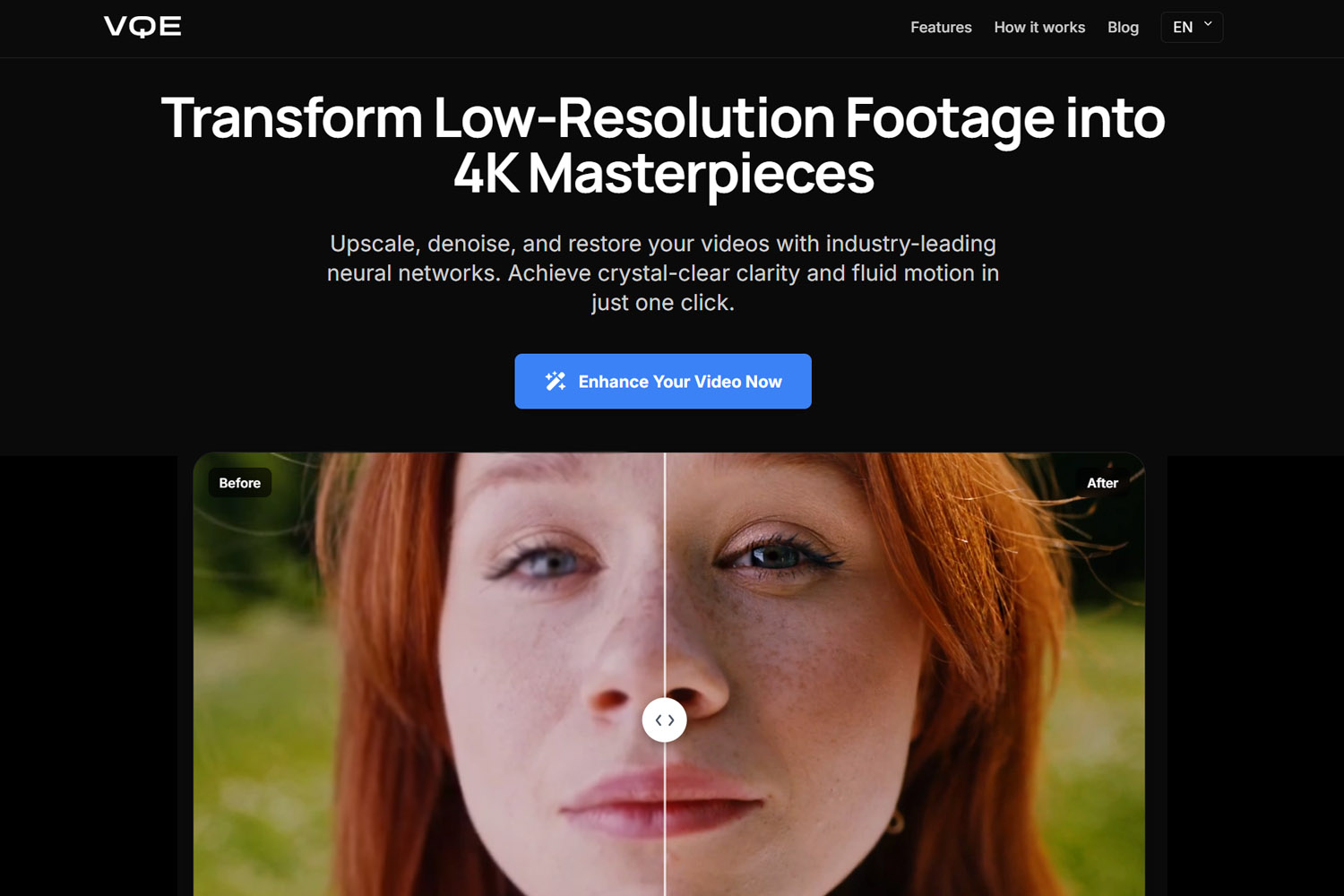
Poza memem "Ulepsz" z CSI
Mem "Ulepsz!" z seriali kryminalnych reprezentuje niemożliwą fantazję z 2005 roku, która w końcu jest częściowo osiągalna w 2026. W 2005 roku interpolacja matematyczna mogła tylko rozciągać istniejące piksele. Nie mogła tworzyć nowych detali. Technologia po prostu nie istniała, aby rekonstruować brakujące informacje w przekonujący sposób.
Nowoczesne AI całkowicie zmienia to równanie. AI nie odzyskuje utraconych pikseli. Zamiast tego zastępuje je lepszymi na podstawie wyuczonych wzorców wizualnych. Kiedy podajesz wideo niskiej rozdzielczości do narzędzia poprawy AI, sieć neuronowa rozpoznaje wzorce (twarze, tekstury, obiekty) i generuje wiarygodne detale, które pasują do wysokiej jakości danych treningowych. To nie jest przywracanie. To inteligentna rekonstrukcja.
Paradoks oryginalnych danych
Fundamentalny paradoks poprawy wideo: ulepszenie oznacza wiarygodną rekonstrukcję, nie przywracanie. Jeśli wideo zostało nagrane w 480p, nie ma wersji 4K ukrytej w danych. Kamera nigdy nie uchwyciła tych detali. Tradycyjne metody skalowania uznają to ograniczenie, po prostu rozciągając piksele, tworząc większe obrazy bez nowych informacji.
Super-rozdzielczość AI działa inaczej. Zamiast rozciągać piksele, AI analizuje treść i generuje nowe detale, które wyglądają naturalnie i przekonująco. AI rozpoznaje "to jest twarz" i tworzy rzęsy, teksturę skóry i cechy twarzy na podstawie tego, jak twarze pojawiają się w danych treningowych wysokiej rozdzielczości. Rezultat wygląda dramatycznie lepiej, ale to są zrekonstruowane detale, nie odzyskane informacje.

To rozróżnienie ma znaczenie dla zrozumienia, co poprawa AI może i nie może zrobić. AI doskonale radzi sobie, gdy materiał źródłowy zawiera wystarczająco dużo informacji do dokładnego rozpoznawania wzorców, pozwalając sieci neuronowej na wyedukowane przewidywania. Gdy materiał źródłowy jest zbyt zdegradowany, AI ma niewystarczające informacje do pracy, prowadząc do artefaktów i niepewnych rezultatów. Zrozumienie tego progu pomaga zdecydować, kiedy poprawa jest warta próby, niezależnie od tego, czy pracujesz z rozmytym materiałem wymagającym usunięcia rozmycia czy wideo niskiej rozdzielczości wymagającym skalowania.
Tradycyjne skalowanie vs. super-rozdzielczość AI
Zrozumienie różnicy między tradycyjnym skalowaniem a super-rozdzielczością AI wyjaśnia, dlaczego nowoczesne narzędzia produkują dramatycznie lepsze rezultaty i kiedy każde podejście ma sens.
Metody tradycyjne: interpolacja dwusześcienna i Lanczosa
Tradycyjne metody skalowania, takie jak interpolacja dwusześcienna i Lanczosa, działają jak rozciąganie gumki, aż stanie się cieńsza. Te algorytmy wykorzystują formuły matematyczne, aby zgadywać, jakie piksele powinny istnieć między znanymi punktami, tworząc większy obraz poprzez rozłożenie istniejących informacji na więcej pikseli. Algorytm interpolacji dwusześciennej wykorzystuje wielomiany sześcienne do szacowania wartości pikseli, podczas gdy próbkowanie Lanczosa stosuje funkcję sinc z oknem dla gładszych rezultatów.
Proces jest prosty: jeśli masz obraz 1080p i chcesz 4K, algorytm tworzy cztery piksele z każdego oryginalnego piksela, używając interpolacji matematycznej. Więcej pikseli, ale bez nowych informacji. Rezultat jest większy, ale niekoniecznie ostrzejszy, ponieważ rozprzestrzeniasz te same ograniczone informacje na większym płótnie.
To podejście działa akceptowalnie dla małych współczynników skalowania (1,5x lub 2x), ale staje się problematyczne przy większych skalach. Przy skalowaniu 4x metody tradycyjne produkują rozmyte, miękkie rezultaty, ponieważ po prostu nie ma wystarczająco dużo informacji źródłowych, aby tworzyć przekonujące detale wyłącznie poprzez interpolację matematyczną.
Super-rozdzielczość AI: Przemalowywanie z rozmytego szkicu
Super-rozdzielczość AI działa jak przemalowywanie szczegółowego obrazu z rozmytego szkicu. Zamiast rozciągać piksele, AI analizuje wzorce i tekstury, aby generować nowe detale, które pasują do typu treści. Sieć neuronowa rozpoznaje, na co patrzy (twarze, budynki, natura) i tworzy wiarygodne detale na podstawie danych treningowych.

Kluczowa różnica: super-rozdzielczość AI opiera się na wyuczonych wzorcach wizualnych, nie na interpolacji matematycznej. Podczas przetwarzania twarzy niskiej rozdzielczości AI nie tylko rozciąga piksele. Zamiast tego rozpoznaje strukturę twarzy i generuje rzęsy, pory skóry i drobne detale na podstawie tego, jak twarze pojawiają się w danych treningowych wysokiej rozdzielczości.
To podejście produkuje rezultaty, które wyglądają dramatycznie bardziej naturalnie niż tradycyjne skalowanie. AI generuje detale, które pasują do typu treści, tworząc tekstury, krawędzie i drobne struktury, które wyglądają przekonująco dla ludzkich widzów. Detale nie są "prawdziwe" w sensie odzyskania z oryginalnego materiału, ale są wiarygodne i wizualnie lepsze.
Super-rozdzielczość: Termin techniczny
Super-rozdzielczość to termin techniczny dla poprawy rozdzielczości opartej na AI. Odnosi się do procesu zwiększania rozdzielczości przestrzennej ponad to, co uchwycił oryginalny sensor, wykorzystując AI do generowania wiarygodnych detali zamiast po prostu rozciągania pikseli. To odróżnia nowoczesną poprawę AI od tradycyjnych metod skalowania.
Jak nowoczesne narzędzia poprawy wideo AI rzeczywiście działają
Poprawa wideo AI w 2026 nie jest pojedynczym algorytmem. Narzędzia takie jak Topaz Video AI i Video Quality Enhancer łączą wiele wyspecjalizowanych systemów pracujących razem, aby poprawić różne aspekty jakości wideo. Zrozumienie tych komponentów pomaga wyjaśnić, dlaczego nowoczesne narzędzia produkują lepsze rezultaty niż wcześniejsze wersje.
Poprawa przestrzenna: skalowanie rozdzielczości
Poprawa przestrzenna zwiększa rozdzielczość poprzez skalowanie z niższych rozdzielczości (720p, 1080p) do wyższych (1080p, 4K). AI rekonstruuje brakujące detale zamiast rozciągać piksele, analizując wzorce i tekstury, aby generować wiarygodne informacje wysokiej rozdzielczości.
Proces działa poprzez rozpoznawanie typów treści i generowanie odpowiednich detali. Twarz otrzymuje cechy twarzy, teksturę skóry i drobne detale. Budynek otrzymuje detale architektoniczne, tekstury i elementy strukturalne. AI wykorzystuje dane treningowe, aby przewidzieć, jak wyglądałyby wersje wyższej rozdzielczości, tworząc rezultaty, które wydają się naturalne i przekonujące.
To działa szczególnie dobrze dla współczynników skalowania od 2x do 4x, gdzie AI ma wystarczająco dużo informacji źródłowych, aby dokonywać dokładnych przewidywań. Ponad 4x rezultaty stają się mniej niezawodne, ponieważ AI ma niewystarczające informacje do pracy, prowadząc do artefaktów i nierealistycznych detali.
Poprawa czasowa: ruch i interpolacja klatek
Poprawa czasowa poprawia płynność ruchu poprzez generowanie klatek pośrednich, konwertując materiał 24fps do 60fps lub tworząc efekty zwolnionego tempa. AI generuje klatki pośrednie, zachowując naturalny ruch, analizując wzorce ruchu, aby tworzyć realistyczne klatki pośrednie.
To działa poprzez zrozumienie, jak obiekty poruszają się w przestrzeni. AI analizuje wektory ruchu między klatkami i przewiduje, jak powinny wyglądać klatki pośrednie, tworząc płynny ruch, który wygląda naturalnie, a nie sztucznie interpolowany. Rezultatem jest płynne odtwarzanie, które eliminuje szarpanie w materiale o niskiej liczbie klatek na sekundę.
Interpolacja klatek jest szczególnie skuteczna dla prostego, przewidywalnego ruchu, takiego jak chodzenie, jazda samochodem lub panoramowanie kamery. Złożone sceny z wieloma nakładającymi się obiektami lub szybkim rozmyciem ruchu mogą tworzyć artefakty, ale dobrze zaimplementowana poprawa czasowa produkuje przekonujące rezultaty.
Inteligentna redukcja szumów: oddzielanie ziarna od szumu
Inteligentna redukcja szumów rozróżnia ziarno filmowe (dobra tekstura) i szum cyfrowy (złe artefakty), zachowując naturalną teksturę przy usuwaniu niechcianego szumu. AI analizuje wzorce w wielu klatkach, aby zidentyfikować, co jest szumem, a co prawdziwym detalem, pozwalając na selektywne usuwanie, które utrzymuje jakość wizualną.

To działa, ponieważ szum ma specyficzne charakterystyki: jest losowy, zmienia się między klatkami i pojawia się jako ziarno lub plamki kolorów. Prawdziwe detale są spójne i podążają za wzorcami, pozwalając AI rozróżnić między nimi. Analizując wiele klatek razem, AI może usuwać szum, zachowując tekstury, krawędzie i ważne detale.
Rezultatem jest czystszy materiał, który utrzymuje naturalny wygląd, unikając plastikowego, nadmiernie wygładzonego wyglądu, który produkują tradycyjne metody redukcji szumów. Nowoczesna redukcja szumów AI zachowuje ziarno filmowe, gdy jest to odpowiednie, jednocześnie usuwając szum sensora i artefakty kompresji.
Przywracanie i dopracowanie twarzy
Przywracanie twarzy wykorzystuje wyspecjalizowane modele neuronowe przeszkolone na strukturze twarzy, aby poprawiać twarze przy zachowaniu naturalnego wyglądu. Te modele stabilizują oczy, teksturę skóry i wyrazy, zapobiegając problemowi "woskowej skóry", który nęka uniwersalne narzędzia do skalowania.

Profesjonalne narzędzia wykorzystują modele specyficzne dla twarzy, ponieważ ludzkie mózgi intensywnie skupiają się na twarzach. Jeśli twarze wyglądają źle, całe wideo wydaje się nieprawidłowe, nawet jeśli tła są doskonale poprawione. Modele przywracania twarzy rozpoznają anatomię twarzy i generują detale, które pasują do naturalnych cech ludzkich, utrzymując realistyczny wygląd przez całą poprawę.
To jest kluczowe dla materiałów z ludźmi, szczególnie wywiadów, portretów lub jakichkolwiek treści, gdzie twarze są prominentne. Bez wyspecjalizowanego przywracania twarzy tła mogą wyglądać na 4K, podczas gdy twarze pozostają rozmyte, tworząc rażące rozłączenie, które sprawia, że całe wideo wygląda gorzej niż oryginał.
AI obrazów vs. AI wideo: Dlaczego wideo jest znacznie trudniejsze
Poprawa wideo jest fundamentalnie bardziej złożona niż poprawa obrazów, ponieważ wideo wymaga spójności czasowej. Detale muszą pozostać stabilne między klatkami, nie tylko dobrze wyglądać w pojedynczym nieruchomym obrazie.
Dlaczego poprawa klatka po klatce zawodzi
Przetwarzanie każdej klatki niezależnie powoduje kilka problemów, które sprawiają, że wideo wygląda gorzej niż oryginał. Każda klatka poprawiona niezależnie tworzy migające tekstury, pełzające detale i niestabilne twarze, które są natychmiast zauważalne podczas odtwarzania.
Problem polega na tym, że niezależne przetwarzanie klatek nie uwzględnia kontekstu. Tekstura może wyglądać ostra w jednej klatce, ale inaczej w następnej, tworząc migający efekt, który jest rozpraszający i nienaturalny. Twarze mogą zmieniać wygląd między klatkami, z oczami lub teksturą skóry przesuwającymi się w sposób, który wygląda źle.
Te artefakty są bardziej zauważalne niż oryginalna niska jakość, czyniąc poprawę klatka po klatce kontrproduktywną. Wideo może mieć wyższą rozdzielczość, ale niespójności czasowe sprawiają, że wygląda gorzej ogólnie.
Prawdziwy przełom: spójność czasowa
Nowoczesne narzędzia poprawy wideo rozwiązują to, analizując wiele klatek razem, zapewniając, że detale pozostają stabilne w czasie. Algorytmy spójności czasowej analizują bieżącą klatkę wraz z kilkoma klatkami przed i po, wykorzystując informacje z otaczających klatek, aby utrzymać stabilność.
Detale muszą pozostać stabilne w czasie, nie tylko dobrze wyglądać w nieruchomym obrazie. To dlatego poważne narzędzia, takie jak Topaz Video AI i platformy chmurowe, takie jak Video Quality Enhancer, mocno skupiają się na analizie czasowej. Proces poprawy uwzględnia całą sekwencję, nie tylko pojedyncze klatki.
Ta świadomość czasowa zapobiega miganiu, pełzaniu i niestabilności. Tekstury pozostają spójne, twarze pozostają stabilne, a ruch wygląda naturalnie, ponieważ AI wykorzystuje informacje z wielu klatek, aby utrzymać spójność. Rezultatem jest poprawa, która wygląda dobrze zarówno w nieruchomych klatkach, jak i podczas odtwarzania.
Modele dyfuzji wyjaśnione
Modele dyfuzji reprezentują znaczący postęp w poprawie wideo AI, oferując lepszą generację detali w porównaniu z wcześniejszymi systemami opartymi na GAN.
Czym naprawdę są modele dyfuzji
Modele dyfuzji to modele generatywne przeszkolone do przewidywania wiarygodnych detali wizualnych poprzez proces iteracyjnego dopracowania. Działają, ucząc się odwracać proces dodawania szumu, stopniowo budując detale z wejść niskiej rozdzielczości lub zaszumionych.
Te modele są niezwykle silne w generowaniu tekstur, twarzy i drobnych struktur, ponieważ są przeszkolone na ogromnych zbiorach danych wysokiej jakości obrazów i wideo. Proces treningowy uczy je rozpoznawać wzorce i generować detale, które pasują do naturalnego wyglądu, produkując rezultaty, które wyglądają przekonująco dla ludzkich widzów.
Stable Diffusion: model obrazów, nie natywny wideo
Stable Diffusion to model obrazów, nie natywny model wideo, co tworzy wyzwania przy stosowaniu go do poprawy wideo. Gdy używany do wideo, modele dyfuzji są zazwyczaj stosowane klatka po klatce, a następnie łączone z przewodnictwem czasowym, aby zmniejszyć miganie.
To podejście hybrydowe działa, ale nie jest idealne. Dyfuzja klatka po klatce może tworzyć niespójności czasowe, wymagając dodatkowego przetwarzania, aby utrzymać stabilność między klatkami. Przewodnictwo czasowe pomaga, ale to obejście dla modelu, który nie został zaprojektowany do wideo.
Najnowsza technologia 2026: hybrydowe potoki
Zaawansowane narzędzia w 2026 wykorzystują hybrydowe potoki, które łączą klasyczną super-rozdzielczość wideo z dopracowaniem detali opartym na dyfuzji. To podejście wykracza poza starsze systemy oparte wyłącznie na GAN, wykorzystując mocne strony zarówno metod klasycznych, jak i generatywnych.
Podejście hybrydowe działa poprzez wykorzystanie klasycznej super-rozdzielczości do podstawowej poprawy, a następnie zastosowanie modeli dyfuzji do dopracowania detali. To produkuje rezultaty, które są zarówno stabilne (z metod klasycznych), jak i szczegółowe (z modeli dyfuzji), tworząc poprawę, która wygląda naturalnie i przekonująco.
Kiedy AI idzie za daleko: problem "fałszywego" wyglądu
Poprawa AI może produkować artefakty, które sprawiają, że wideo wygląda sztucznie, szczególnie gdy przetwarzanie jest zbyt agresywne lub gdy materiał źródłowy jest zbyt zdegradowany.
Typowe tryby awarii
Artefakty występują, gdy AI błędnie interpretuje wzorce, tworząc detale, które nie pasują do treści. Cegły mogą pojawić się tam, gdzie ich nie ma, tekstury tkanin mogą być generowane nieprawidłowo lub wzorce mogą być tworzone, które wyglądają nienaturalnie.
Woskowa skóra występuje, gdy AI usuwa naturalne pory i teksturę, tworząc plastikowy wygląd, który jest natychmiast zauważalny. To dzieje się, gdy algorytmy poprawy wygładzają zbyt agresywnie, usuwając drobne wariacje, które sprawiają, że skóra wygląda realistycznie.
Nadmierne wyostrzanie tworzy detale, które wyglądają jak namalowane, z krawędziami, które są zbyt ostre i teksturami, które wydają się sztuczne. Detale mogą być technicznie "prawidłowe", ale nie pasują do naturalnego wyglądu, tworząc efekt doliny niesamowitości.
Nowoczesne rozwiązanie: kontrolowana poprawa
Profesjonalne narzędzia rozwiązują te problemy poprzez kontrolowaną siłę poprawy i zachowanie ziarna filmowego. Kontrolowana poprawa pozwala użytkownikom dostosować intensywność przetwarzania, znajdując równowagę między ulepszeniem a naturalnym wyglądem.
Zachowanie lub ponowne wstrzyknięcie ziarna filmowego utrzymuje naturalną teksturę, która może zostać utracona podczas przetwarzania. Niektóre narzędzia mogą analizować i zachowywać oryginalne ziarno lub dodawać syntetyczne ziarno z powrotem po poprawie, utrzymując naturalny wygląd, którego oczekują widzowie.
Profesjonalne narzędzia udostępniają kontrolki dostrajania, aby uniknąć nadmiernego przetwarzania, dając użytkownikom kontrolę nad parametrami poprawy. To pozwala na precyzyjne dostrajanie, które produkuje naturalne rezultaty, a nie poprawę wyglądającą sztucznie.
Benchmarki rzeczywiste: Co różne narzędzia mogą osiągnąć
Zrozumienie, co różne narzędzia mogą rzeczywiście osiągnąć, pomaga ustalić realistyczne oczekiwania i wybrać właściwe podejście dla swojego materiału.
Źródła niskiej jakości: VHS, MiniDV, 480p
Źródła niskiej jakości pokazują dużą poprawę percepcyjną, gdy poprawiane nowoczesnymi narzędziami AI. Taśmy VHS, materiały MiniDV i wideo 480p mogą być skalowane do 1080p lub 4K z rezultatami, które wyglądają dramatycznie lepiej niż oryginał.
Rezultaty są nadal stylizowane, nie magicznie nowoczesne. Poprawiony materiał utrzymuje charakter oryginału, jednocześnie wyglądając znacznie ostrzej i czyściej. AI nie może całkowicie wyeliminować ograniczeń materiału źródłowego, ale może tworzyć rezultaty, które są wizualnie lepsze i bardziej oglądalne.
To działa najlepiej, gdy materiał źródłowy ma minimalne artefakty kompresji i rozsądne ogniskowanie. Ciężko zdegradowany materiał z ciężką kompresją lub rozmyciem ruchu wyprodukuje mniej imponujące rezultaty, ale nawet w tych przypadkach nowoczesne narzędzia mogą tworzyć zauważalną poprawę. Gdy masz do czynienia z rozmytym materiałem, zrozumienie typu rozmycia pomaga określić, czy poprawa będzie skuteczna.
Źródła średniej jakości: smartfony 1080p, aparaty DSLR
Źródła średniej jakości osiągają niemal natywną jakość percepcyjną 4K, gdy poprawiane profesjonalnymi narzędziami. Nowoczesne materiały ze smartfonów i wideo DSLR nagrane w 1080p mogą być skalowane do 4K z rezultatami, które wyglądają niemal tak dobrze jak natywny materiał 4K.
To tutaj narzędzia takie jak Topaz Video AI i Video Quality Enhancer świecą najbardziej. Materiał źródłowy zawiera wystarczająco dużo informacji do dokładnych przewidywań AI, pozwalając narzędziom generować detale, które wyglądają naturalnie i przekonująco. Poprawiony materiał utrzymuje charakter oryginału, jednocześnie osiągając wyższą rozdzielczość i postrzeganą jakość.
Kluczem jest rozpoczęcie od przyzwoitego materiału źródłowego. Wideo 1080p nagrane przy wysokim bitrate będzie skalować się lepiej niż wideo 1080p nagrane przy niskim bitrate, ponieważ wyższy bitrate zachowuje więcej informacji dla AI do pracy.
Metryki vs. wizja ludzka: Dlaczego "wygląda lepiej" ma znaczenie
Wideo poprawione przez AI może mieć niższe wyniki w metrykach technicznych, takich jak VMAF, podczas gdy wygląda dramatycznie lepiej dla ludzkich widzów. Ten paradoks ujawnia, dlaczego jakość percepcyjna ma większe znaczenie niż dokładność na poziomie pikseli.
Paradoks dokładności
Wideo poprawione przez AI może mieć niższe wyniki w metrykach, takich jak VMAF, ponieważ proces poprawy tworzy detale, których nie było w oryginale. Metryki techniczne mierzą dokładność do źródła, ale poprawa AI celowo tworzy nowe detale, co może obniżyć wyniki dokładności. Metryka VMAF (Video Multi-method Assessment Fusion) opracowana przez Netflix łączy wiele pomiarów jakości, aby przewidzieć percepcję ludzką, ale mierzy wierność do źródła, a nie poprawę percepcyjną.
Jednak poprawione wideo wygląda dramatycznie lepiej dla ludzkich widzów, którzy bardziej dbają o klarowność, twarze i stabilność ruchu niż o dokładność na poziomie pikseli. To tworzy sytuację, w której metryki techniczne sugerują niższą jakość, ale percepcja ludzka wskazuje na wyższą jakość.
Dlaczego to się dzieje
AI priorytetyzuje jakość percepcyjną, nie dokładność na poziomie pikseli. Proces poprawy jest zaprojektowany, aby tworzyć rezultaty, które wyglądają dobrze dla ludzi, nie aby pasować do oryginału piksel po pikselu. To oznacza, że AI może generować detale, które poprawiają postrzeganą jakość, nawet jeśli zmniejszają dokładność techniczną.
Ludzie bardziej dbają o klarowność, twarze i stabilność ruchu niż o to, czy każdy piksel pasuje do oryginału. Jeśli twarz wygląda ostrzej i bardziej naturalnie, widzowie postrzegają wyższą jakość, nawet jeśli poprawiona wersja nie pasuje do oryginału piksel za piksel. Jeśli nie jesteś pewien, czy Twój materiał jest odpowiedni do poprawy, ChatGPT może pomóc przeanalizować jakość Twojego wideo i zalecić właściwe podejście.
To rozróżnienie ma znaczenie dla zrozumienia rezultatów poprawy. Metryki techniczne zapewniają jedną perspektywę, ale percepcja ludzka zapewnia inną, a dla poprawy wideo percepcja ludzka jest tym, co ostatecznie ma znaczenie.
Jak stwierdzić, czy narzędzie poprawy wideo jest rzeczywiście dobre
Większość recenzji skupia się na jakości wyjściowej, ale pomija krytyczne czynniki, które określają, czy poprawa rzeczywiście poprawia wideo czy wprowadza nowe problemy.
Testy, które większość recenzji pomija
Testowanie migania czasowego sprawdza, czy tekstury migają między klatkami. Dobre narzędzie poprawy utrzymuje stabilne tekstury przez całe wideo, podczas gdy słabe narzędzia tworzą miganie, które jest natychmiast zauważalne podczas odtwarzania.
Testowanie stabilności twarzy weryfikuje, czy oczy i skóra pozostają spójne między klatkami. Twarze powinny wyglądać stabilnie i naturalnie przez całe wideo, nie zmieniając wyglądu między klatkami w sposób, który wygląda źle.
Testowanie integralności ruchu zapewnia brak zniekształceń podczas szybkiego ruchu. Poprawione wideo powinno utrzymywać naturalny ruch, z obiektami poruszającymi się płynnie bez zniekształceń lub artefaktów podczas szybkiej akcji.
Wglądy na poziomie profesjonalnym
Analiza klatek referencyjnych ujawnia, jak AI pożycza detale z pobliskich ostrych klatek. Zaawansowane narzędzia analizują wiele klatek, aby znaleźć najostrzejszą wersję każdego elementu, a następnie wykorzystują te informacje do poprawy innych klatek. To tworzy dokładniejszą poprawę niż przetwarzanie każdej klatki niezależnie.
Unikanie "przegotowania" oznacza, że subtelna poprawa bije agresywną rekonstrukcję. Najlepsze rezultaty pochodzą z umiarkowanej poprawy, która poprawia jakość bez wprowadzania artefaktów. Agresywne przetwarzanie może tworzyć więcej detali, ale często wygląda sztucznie i zmniejsza ogólną jakość.
Rzeczywistość sprzętowa: narzędzia lokalne wymagają wydajnych kart graficznych, podczas gdy platformy chmurowe całkowicie usuwają tę barierę. Oprogramowanie desktopowe, takie jak Topaz Video AI, potrzebuje serii NVIDIA RTX lub kart graficznych Apple Silicon dla praktycznych prędkości przetwarzania. Rozwiązania chmurowe, takie jak Video Quality Enhancer, eliminują wymagania sprzętowe, czyniąc profesjonalną poprawę dostępną niezależnie od lokalnej konfiguracji. Jeśli pracujesz z ChatGPT, aby kierować swoim przepływem pracy poprawy, może pomóc wybrać między podejściami lokalnymi i chmurowymi na podstawie Twojego sprzętu.
Ostateczny werdykt: Czy AI naprawdę może poprawić jakość wideo?
Odpowiedź brzmi tak, ale z ważnymi zastrzeżeniami, które wyjaśniają, kiedy poprawa działa, a kiedy nie.
AI nie przywraca utraconej rzeczywistości
AI nie przywraca utraconej rzeczywistości. Zamiast tego rekonstruuje wiarygodne detale. Jeśli wideo zostało nagrane w 480p, nie ma wersji 4K ukrytej w danych. Kamera nigdy nie uchwyciła tych detali. Poprawa AI tworzy wiarygodne detale na podstawie danych treningowych, nie odzyskanych informacji.
To rozróżnienie ma znaczenie dla zrozumienia, co poprawa może osiągnąć. Poprawione wideo reprezentuje to, co AI myśli, że powinno tam być, niekoniecznie to, co zostało rzeczywiście uchwycone. To jest rekonstrukcja, nie przywracanie.
Gdy wykonane prawidłowo, rezultaty są stabilne, naturalne i wizualnie lepsze
Gdy wykonane prawidłowo, poprawa AI produkuje rezultaty, które są stabilne, naturalne i wizualnie lepsze. Nowoczesne narzędzia ze spójnością czasową tworzą poprawę, która wygląda dobrze zarówno w nieruchomych klatkach, jak i podczas odtwarzania, utrzymując naturalny wygląd przez cały czas.
Kluczem jest użycie właściwego narzędzia dla swojego materiału źródłowego i zastosowanie odpowiedniej siły poprawy. Profesjonalne narzędzia z właściwą analizą czasową produkują rezultaty, które wyglądają przekonująco i naturalnie, unikając artefaktów i niestabilności, które nękają przetwarzanie klatka po klatce.
Poprawa wideo AI nie dotyczy prawdy: dotyczy przekonującej klarowności
Poprawa wideo AI nie dotyczy prawdy. Dotyczy przekonującej klarowności. Celem nie jest odzyskanie utraconych informacji, ale stworzenie rezultatów, które wyglądają lepiej dla ludzkich widzów. Jeśli poprawione wideo wygląda ostrzej, czyściej i bardziej naturalnie, osiągnęło swój cel, nawet jeśli detale są technicznie "zhalucynowane".
Ta perspektywa pomaga ustalić realistyczne oczekiwania. Poprawa AI tworzy wiarygodne, wizualnie lepsze rezultaty, nie doskonałe rekonstrukcje utraconych informacji. Technologia działa najlepiej, gdy materiał źródłowy zawiera wystarczająco dużo informacji do dokładnego rozpoznawania wzorców, pozwalając AI generować detale, które wyglądają naturalnie i przekonująco.