L'AI Può Davvero Migliorare la Qualità Video?

La domanda "L'AI può davvero migliorare la qualità video?" ha una risposta complessa che va oltre un semplice sì o no. L'AI moderna non ripristina pixel persi. Invece, li sostituisce con altri migliori attraverso ricostruzione intelligente. Questa distinzione conta perché spiega perché il miglioramento AI funziona magnificamente in alcuni scenari mentre fallisce in altri, e perché i risultati sembrano convincenti anche se sono tecnicamente dettaglio "allucinato".
Questo articolo esplora la scienza dietro il miglioramento video AI, dalla differenza fondamentale tra upscaling tradizionale e super-risoluzione AI al breakthrough della coerenza temporale che rende gli strumenti moderni fattibili. Esamineremo come strumenti come Topaz Video AI e piattaforme cloud elaborano video, perché il miglioramento video è più difficile del miglioramento immagini, e cosa rivelano i benchmark sui risultati nel mondo reale.
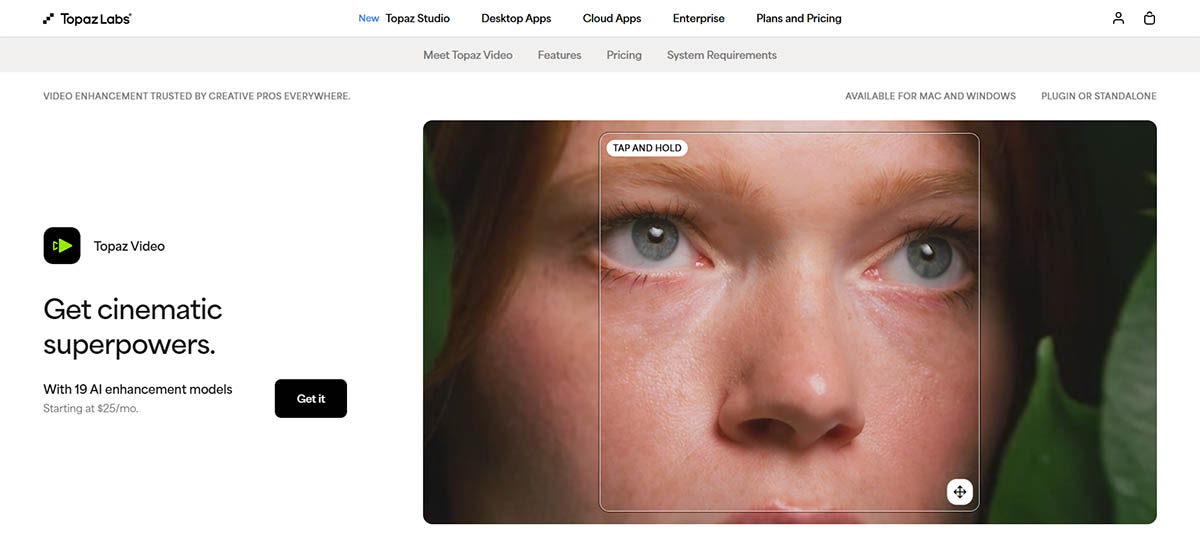
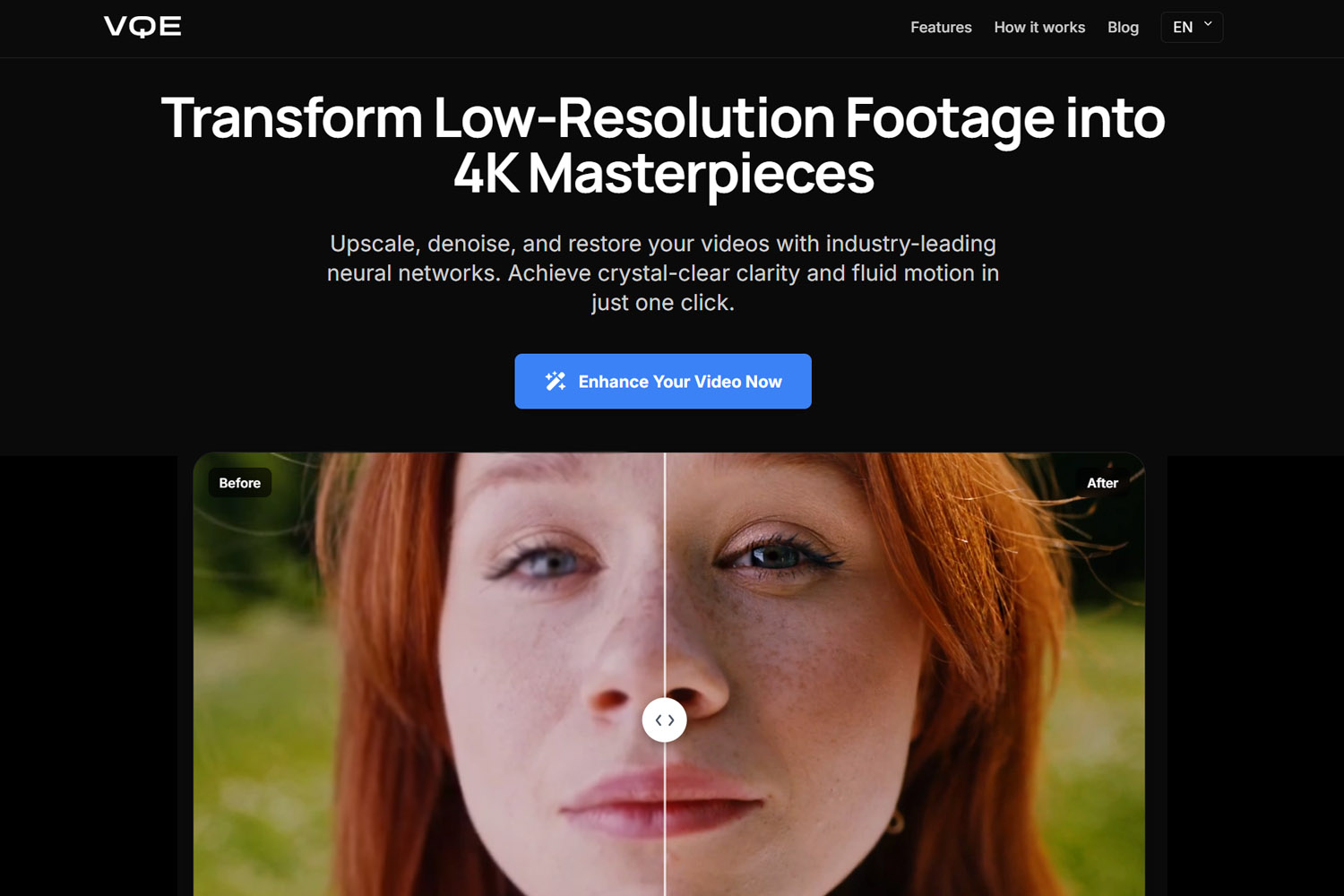
Oltre il Meme "Enhance" di CSI
Il meme "Enhance!" degli show polizieschi rappresenta una fantasia impossibile del 2005 che è finalmente parzialmente raggiungibile nel 2026. Nel 2005, l'interpolazione matematica poteva solo allungare pixel esistenti. Non poteva creare nuovo dettaglio. La tecnologia semplicemente non esisteva per ricostruire informazioni mancanti in modo convincente.
L'AI moderna cambia completamente questa equazione. L'AI non recupera pixel persi. Invece, li sostituisce con altri migliori basandosi su pattern visivi appresi. Quando dai un video a bassa risoluzione a un miglioratore AI, la rete neurale riconosce pattern (volti, texture, oggetti) e genera dettaglio plausibile che corrisponde a dati di addestramento di alta qualità. Questo non è ripristino. È ricostruzione intelligente.
Il Paradosso dei Dati Originali
Il paradosso fondamentale del miglioramento video: il miglioramento significa ricostruzione plausibile, non ripristino. Se un video è stato registrato a 480p, non c'è una versione 4K nascosta nei dati. La fotocamera non ha mai catturato quel dettaglio. I metodi di upscaling tradizionali riconoscono questa limitazione semplicemente allungando i pixel, creando immagini più grandi senza nuove informazioni.
La super-risoluzione AI funziona diversamente. Invece di allungare i pixel, l'AI analizza il contenuto e genera nuovo dettaglio che sembra naturale e convincente. L'AI riconosce "questo è un volto" e crea ciglia, texture della pelle e caratteristiche facciali basandosi su come i volti appaiono nei dati di addestramento ad alta risoluzione. Il risultato sembra drasticamente migliore, ma è dettaglio ricostruito, non informazioni recuperate.

Questa distinzione conta per comprendere cosa il miglioramento AI può e non può fare. L'AI eccelle quando il materiale sorgente contiene abbastanza informazioni per il riconoscimento accurato dei pattern, permettendo alla rete neurale di fare previsioni informate. Quando il materiale sorgente è troppo degradato, l'AI ha informazioni insufficienti con cui lavorare, portando ad artefatti e risultati inaffidabili. Comprendere questa soglia ti aiuta a decidere quando il miglioramento vale la pena tentare, sia che tu stia lavorando con riprese sfocate che hanno bisogno di deblurring o video a bassa risoluzione che hanno bisogno di upscaling.
Upscaling Tradizionale vs Super-Risoluzione AI
Comprendere la differenza tra upscaling tradizionale e super-risoluzione AI spiega perché gli strumenti moderni producono risultati drasticamente migliori e quando ogni approccio ha senso.
Metodi Tradizionali: Interpolazione Bicubica e Lanczos
I metodi di upscaling tradizionali come l'interpolazione bicubica e Lanczos funzionano come allungare un elastico finché non diventa più sottile. Questi algoritmi usano formule matematiche per indovinare quali pixel dovrebbero esistere tra punti noti, creando un'immagine più grande distribuendo informazioni esistenti su più pixel. L'algoritmo di interpolazione bicubica usa polinomi cubici per stimare valori di pixel, mentre il resampling Lanczos applica una funzione sinc finestrata per risultati più lisci.
Il processo è semplice: se hai un'immagine 1080p e vuoi 4K, l'algoritmo crea quattro pixel da ogni pixel originale usando interpolazione matematica. Più pixel, ma nessuna nuova informazione. Il risultato è più grande ma non necessariamente più nitido, perché stai diffondendo le stesse informazioni limitate su una tela più grande.
Questo approccio funziona accettabilmente per piccoli fattori di upscaling (1.5x o 2x), ma diventa problematico a scale più grandi. A upscaling 4x, i metodi tradizionali producono risultati sfocati e morbidi perché semplicemente non c'è abbastanza informazione sorgente per creare dettaglio convincente solo attraverso interpolazione matematica.
Super-Risoluzione AI: Ridipingere da uno Schizzo Sfocato
La super-risoluzione AI funziona come ridipingere un'immagine dettagliata da uno schizzo sfocato. Invece di allungare i pixel, l'AI analizza pattern e texture per generare nuovo dettaglio che si adatta al tipo di contenuto. La rete neurale riconosce cosa sta guardando (volti, edifici, natura) e crea dettaglio plausibile basandosi sui dati di addestramento.

La differenza chiave: la super-risoluzione AI è basata su pattern visivi appresi, non interpolazione matematica. Quando elabora un volto a bassa risoluzione, l'AI non allunga semplicemente i pixel. Invece, riconosce la struttura facciale e genera ciglia, pori della pelle e dettagli fini basandosi su come i volti appaiono nei dati di addestramento ad alta risoluzione.
Questo approccio produce risultati che sembrano drasticamente più naturali dell'upscaling tradizionale. L'AI genera dettaglio che corrisponde al tipo di contenuto, creando texture, bordi e strutture fini che sembrano convincenti agli spettatori umani. Il dettaglio non è "reale" nel senso di essere recuperato dalle riprese originali, ma è plausibile e visivamente superiore.
Super-Risoluzione: Il Termine Tecnico
La super-risoluzione è il termine tecnico per il miglioramento della risoluzione basato su AI. Si riferisce al processo di aumentare la risoluzione spaziale oltre ciò che il sensore originale ha catturato, usando l'AI per generare dettaglio plausibile piuttosto che semplicemente allungare i pixel. Questo distingue il miglioramento AI moderno dai metodi di upscaling tradizionali.
Come Funzionano Realmente gli Strumenti di Miglioramento Video AI Moderni
Il miglioramento video AI nel 2026 non è un singolo algoritmo. Strumenti come Topaz Video AI e Video Quality Enhancer combinano più sistemi specializzati che lavorano insieme per migliorare diversi aspetti della qualità video. Comprendere questi componenti aiuta a spiegare perché gli strumenti moderni producono risultati migliori delle versioni precedenti.
Miglioramento Spaziale: Upscaling della Risoluzione
Il miglioramento spaziale aumenta la risoluzione facendo upscaling da risoluzioni inferiori (720p, 1080p) a superiori (1080p, 4K). L'AI ricostruisce dettaglio mancante invece di allungare i pixel, analizzando pattern e texture per generare informazioni ad alta risoluzione plausibili.
Il processo funziona riconoscendo tipi di contenuto e generando dettaglio appropriato. Un volto ottiene caratteristiche facciali, texture della pelle e dettagli fini. Un edificio ottiene dettagli architettonici, texture ed elementi strutturali. L'AI usa dati di addestramento per prevedere come sarebbero le versioni ad alta risoluzione, creando risultati che appaiono naturali e convincenti.
Questo funziona particolarmente bene per fattori di upscaling da 2x a 4x, dove l'AI ha abbastanza informazioni sorgente per fare previsioni accurate. Oltre 4x, i risultati diventano meno affidabili perché l'AI ha informazioni insufficienti con cui lavorare, portando ad artefatti e dettaglio irrealistico.
Miglioramento Temporale: Movimento e Interpolazione di Fotogrammi
Il miglioramento temporale migliora la fluidità del movimento generando fotogrammi intermedi, convertendo riprese a 24fps a 60fps o creando effetti slow-motion. L'AI genera fotogrammi intermedi preservando movimento naturale, analizzando pattern di movimento per creare fotogrammi intermedi realistici.
Questo funziona comprendendo come gli oggetti si muovono attraverso lo spazio. L'AI analizza vettori di movimento tra i fotogrammi e prevede come dovrebbero sembrare i fotogrammi intermedi, creando movimento fluido che sembra naturale piuttosto che artificialmente interpolato. Il risultato è riproduzione fluida che elimina la scattosità nelle riprese a basso frame rate.
L'interpolazione di fotogrammi è particolarmente efficace per movimento semplice e prevedibile come camminare, guidare o panning della fotocamera. Scene complesse con molti oggetti sovrapposti o motion blur veloce possono creare artefatti, ma il miglioramento temporale ben implementato produce risultati convincenti.
Denoising Intelligente: Separare Grana da Rumore
Il denoising intelligente distingue tra grana cinematografica (texture buona) e rumore digitale (artefatti cattivi), preservando texture naturale mentre rimuove rumore indesiderato. L'AI analizza pattern attraverso più fotogrammi per identificare cosa è rumore rispetto a cosa è dettaglio reale, permettendo rimozione selettiva che mantiene qualità visiva.

Questo funziona perché il rumore ha caratteristiche specifiche: è casuale, cambia tra i fotogrammi e appare come grana o macchie di colore. Il dettaglio reale è coerente e segue pattern, permettendo all'AI di distinguere tra i due. Analizzando più fotogrammi insieme, l'AI può rimuovere il rumore preservando texture, bordi e dettagli importanti.
Il risultato sono riprese più pulite che mantengono aspetto naturale, evitando l'aspetto plastico, eccessivamente levigato che i metodi di denoising tradizionali producono. Il denoising AI moderno preserva la grana cinematografica quando appropriato mentre rimuove rumore del sensore e artefatti di compressione.
Recupero e Raffinamento Volto
Il recupero volto usa modelli neurali specializzati addestrati sulla struttura facciale per migliorare i volti mantenendo aspetto naturale. Questi modelli stabilizzano occhi, texture della pelle ed espressioni, prevenendo il problema della "pelle cerosa" che affligge gli upscaler generici.

Gli strumenti professionali usano modelli specifici per i volti perché i cervelli umani si concentrano intensamente sui volti. Se i volti sembrano sbagliati, l'intero video sembra strano, anche se gli sfondi sono perfettamente migliorati. I modelli di recupero volto riconoscono l'anatomia facciale e generano dettaglio che corrisponde a caratteristiche umane naturali, mantenendo aspetto realistico durante tutto il miglioramento.
Questo è cruciale per riprese con persone, specialmente interviste, ritratti o qualsiasi contenuto dove i volti sono prominenti. Senza recupero volto specializzato, gli sfondi potrebbero sembrare 4K mentre i volti rimangono sfocati, creando una disconnessione stridente che fa sembrare l'intero video peggiore dell'originale.
AI Immagini vs AI Video: Perché il Video è Molto Più Difficile
Migliorare il video è fondamentalmente più complesso del migliorare immagini perché il video richiede coerenza temporale. Il dettaglio deve rimanere stabile tra i fotogrammi, non solo sembrare buono in una singola immagine ferma.
Perché il Miglioramento Fotogramma per Fotogramma Fallisce
Elaborare ogni fotogramma indipendentemente causa diversi problemi che fanno sembrare il video peggiore dell'originale. Ogni fotogramma migliorato indipendentemente crea texture sfarfallanti, dettaglio strisciante e volti instabili che sono immediatamente notabili durante la riproduzione.
Il problema è che l'elaborazione indipendente dei fotogrammi non considera il contesto. Una texture potrebbe sembrare nitida in un fotogramma ma diversa nel successivo, creando un effetto scintillante che è distraente e innaturale. I volti potrebbero cambiare aspetto tra i fotogrammi, con occhi o texture della pelle che cambiano in modi che sembrano sbagliati.
Questi artefatti sono più notabili della qualità bassa originale, rendendo il miglioramento fotogramma per fotogramma controproducente. Il video potrebbe avere risoluzione più alta, ma le inconsistenze temporali lo fanno sembrare peggiore complessivamente.
Il Breakthrough Reale: Coerenza Temporale
Gli strumenti di miglioramento video moderni risolvono questo analizzando più fotogrammi insieme, garantendo che il dettaglio rimanga stabile nel tempo. Gli algoritmi di coerenza temporale analizzano il fotogramma corrente insieme a diversi fotogrammi prima e dopo, usando informazioni dai fotogrammi circostanti per mantenere la stabilità.
Il dettaglio deve rimanere stabile nel tempo, non solo sembrare buono in un'immagine ferma. Questo è il motivo per cui strumenti seri come Topaz Video AI e piattaforme cloud come Video Quality Enhancer si concentrano pesantemente sull'analisi temporale. Il processo di miglioramento considera l'intera sequenza, non solo fotogrammi individuali.
Questa consapevolezza temporale previene flickering, strisciamento e instabilità. Le texture rimangono coerenti, i volti rimangono stabili e il movimento sembra naturale perché l'AI usa informazioni da più fotogrammi per mantenere coerenza. Il risultato è miglioramento che sembra buono sia in fotogrammi fermi che durante la riproduzione.
Modelli Diffusion Spiegati
I modelli diffusion rappresentano un avanzamento significativo nel miglioramento video AI, offrendo generazione di dettaglio superiore rispetto ai sistemi basati su GAN precedenti.
Cosa Sono Realmente i Modelli Diffusion
I modelli diffusion sono modelli generativi addestrati a prevedere dettaglio visivo plausibile attraverso un processo di raffinamento iterativo. Funzionano imparando a invertire un processo di aggiunta di rumore, costruendo gradualmente dettaglio da input a bassa risoluzione o rumorosi.
Questi modelli sono estremamente forti nel generare texture, volti e strutture fini perché sono addestrati su vasti dataset di immagini e video di alta qualità. Il processo di addestramento insegna loro a riconoscere pattern e generare dettaglio che corrisponde all'aspetto naturale, producendo risultati che sembrano convincenti agli spettatori umani.
Stable Diffusion: Modello Immagine, Non Video Nativo
Stable Diffusion è un modello immagine, non un modello video nativo, il che crea sfide quando lo si applica al miglioramento video. Quando usato per video, i modelli diffusion sono tipicamente applicati fotogramma per fotogramma, poi combinati con guida temporale per ridurre il flicker.
Questo approccio ibrido funziona ma non è ideale. Il diffusion fotogramma per fotogramma può creare inconsistenze temporali, richiedendo elaborazione aggiuntiva per mantenere la stabilità tra i fotogrammi. La guida temporale aiuta, ma è un workaround per un modello che non è stato progettato per video.
Il Taglio Avanzato del 2026: Pipeline Ibride
Strumenti avanzati nel 2026 usano pipeline ibride che combinano super-risoluzione video classica con raffinamento dettaglio basato su diffusion. Questo approccio va oltre i sistemi solo GAN più vecchi, sfruttando i punti di forza di entrambi i metodi classici e generativi.
L'approccio ibrido funziona usando super-risoluzione classica per miglioramento base, poi applicando modelli diffusion per raffinamento dettaglio. Questo produce risultati che sono sia stabili (da metodi classici) che dettagliati (da modelli diffusion), creando miglioramento che sembra naturale e convincente.
Quando l'AI Va Troppo Oltre: Il Problema dell'Aspetto "Falso"
Il miglioramento AI può produrre artefatti che fanno sembrare il video artificiale, specialmente quando l'elaborazione è troppo aggressiva o quando il materiale sorgente è troppo degradato.
Modalità di Fallimento Comuni
L'artefattazione si verifica quando l'AI interpreta erroneamente i pattern, creando dettaglio che non corrisponde al contenuto. Potrebbero apparire mattoni dove non ce ne sono, texture di tessuto potrebbero essere generate incorrettamente, o pattern potrebbero essere creati che sembrano innaturali.
La pelle cerosa accade quando l'AI rimuove pori naturali e texture, creando un aspetto plastico che è immediatamente notabile. Questo si verifica quando gli algoritmi di miglioramento levigano troppo aggressivamente, rimuovendo le variazioni fini che fanno sembrare la pelle reale.
L'over-sharpening crea dettaglio che sembra dipinto, con bordi che sono troppo nitidi e texture che appaiono artificiali. Il dettaglio potrebbe essere tecnicamente "corretto" ma non corrisponde all'aspetto naturale, creando un effetto uncanny valley.
La Soluzione Moderna: Miglioramento Controllato
Gli strumenti professionali affrontano questi problemi attraverso forza di miglioramento controllata e preservazione grana cinematografica. Il miglioramento controllato permette agli utenti di regolare l'intensità dell'elaborazione, trovando l'equilibrio tra miglioramento e aspetto naturale.
La preservazione o re-iniezione grana cinematografica mantiene texture naturale che potrebbe essere persa durante l'elaborazione. Alcuni strumenti possono analizzare e preservare grana originale, o aggiungere grana sintetica dopo il miglioramento, mantenendo l'aspetto naturale che gli spettatori si aspettano.
Gli strumenti professionali espongono controlli di regolazione per evitare over-elaborazione, dando agli utenti controllo sui parametri di miglioramento. Questo permette regolazione fine che produce risultati naturali piuttosto che miglioramento dall'aspetto artificiale.
Benchmark del Mondo Reale: Cosa Possono Raggiungere Diversi Strumenti
Comprendere cosa diversi strumenti possono effettivamente raggiungere aiuta a stabilire aspettative realistiche e scegliere l'approccio giusto per le tue riprese.
Sorgenti di Bassa Qualità: VHS, MiniDV, 480p
Le sorgenti di bassa qualità mostrano grande miglioramento percettivo quando migliorate con strumenti AI moderni. Nastri VHS, riprese MiniDV e video 480p possono essere upscalati a 1080p o 4K con risultati che sembrano drasticamente migliori dell'originale.
I risultati sono ancora stilizzati, non magicamente moderni. Le riprese migliorate mantengono il carattere dell'originale mentre sembrano significativamente più nitide e pulite. L'AI non può eliminare completamente le limitazioni del materiale sorgente, ma può creare risultati che sono visivamente superiori e più guardabili.
Questo funziona meglio quando il materiale sorgente ha artefatti di compressione minimi e messa a fuoco ragionevole. Riprese pesantemente degradate con compressione severa o motion blur produrranno risultati meno impressionanti, ma anche in questi casi, gli strumenti moderni possono creare miglioramento notabile. Quando si ha a che fare con riprese sfocate, comprendere il tipo di sfocatura aiuta a determinare se il miglioramento sarà efficace.
Sorgenti di Qualità Media: Smartphone 1080p, DSLR
Le sorgenti di qualità media raggiungono qualità percettiva 4K quasi nativa quando migliorate con strumenti professionali. Riprese smartphone moderne e video DSLR registrati a 1080p possono essere upscalati a 4K con risultati che sembrano quasi buoni come riprese 4K native.
Questo è dove strumenti come Topaz Video AI e Video Quality Enhancer brillano di più. Il materiale sorgente contiene abbastanza informazioni per previsioni AI accurate, permettendo agli strumenti di generare dettaglio che sembra naturale e convincente. Le riprese migliorate mantengono il carattere dell'originale mentre raggiungono risoluzione più alta e qualità percepita.
La chiave è iniziare con materiale sorgente decente. Un video 1080p registrato ad alto bitrate farà upscale meglio di un video 1080p registrato a basso bitrate, perché il bitrate più alto preserva più informazioni per l'AI con cui lavorare.
Metriche vs Visione Umana: Perché "Sembra Migliore" Conta
Il video migliorato AI può segnare più basso su metriche tecniche come VMAF mentre sembra drasticamente migliore agli spettatori umani. Questo paradosso rivela perché la qualità percettiva conta più dell'accuratezza a livello di pixel.
Il Paradosso dell'Accuratezza
Il video migliorato AI può segnare più basso su metriche come VMAF perché il processo di miglioramento crea dettaglio che non era nell'originale. Le metriche tecniche misurano accuratezza alla sorgente, ma il miglioramento AI crea intenzionalmente nuovo dettaglio, il che può abbassare i punteggi di accuratezza. La metrica VMAF (Video Multi-method Assessment Fusion) sviluppata da Netflix combina multiple misurazioni di qualità per prevedere la percezione umana, ma misura fedeltà alla sorgente piuttosto che miglioramento percettivo.
Tuttavia il video migliorato sembra drasticamente migliore agli spettatori umani, che si preoccupano più di chiarezza, volti e stabilità del movimento che di accuratezza a livello di pixel. Questo crea una situazione dove le metriche tecniche suggeriscono qualità inferiore, ma la percezione umana indica qualità superiore.
Perché Questo Accade
L'AI dà priorità alla qualità percettiva, non all'accuratezza a livello di pixel. Il processo di miglioramento è progettato per creare risultati che sembrano buoni agli umani, non per corrispondere all'originale pixel per pixel. Questo significa che l'AI potrebbe generare dettaglio che migliora la qualità percepita anche se riduce l'accuratezza tecnica.
Gli umani si preoccupano più di chiarezza, volti e stabilità del movimento che di se ogni pixel corrisponde all'originale. Se un volto sembra più nitido e naturale, gli spettatori percepiscono qualità superiore anche se la versione migliorata non corrisponde all'originale pixel per pixel. Se non sei sicuro se le tue riprese sono adatte al miglioramento, ChatGPT può aiutare ad analizzare la qualità del tuo video e raccomandare l'approccio giusto.
Questa distinzione conta per comprendere i risultati del miglioramento. Le metriche tecniche forniscono una prospettiva, ma la percezione umana ne fornisce un'altra, e per il miglioramento video, la percezione umana è ciò che conta alla fine.
Come Capire Se uno Strumento di Miglioramento Video è Realmente Buono
La maggior parte delle recensioni si concentra sulla qualità dell'output ma ignora fattori critici che determinano se il miglioramento migliora effettivamente il video o introduce nuovi problemi.
I Test Che la Maggior Parte delle Recensioni Ignorano
Il test di flicker temporale verifica se la texture scintilla tra i fotogrammi. Un buon strumento di miglioramento mantiene texture stabili per tutto il video, mentre strumenti scadenti creano flickering che è immediatamente notabile durante la riproduzione.
Il test di stabilità volto verifica se occhi e pelle rimangono coerenti tra i fotogrammi. I volti dovrebbero sembrare stabili e naturali per tutto il video, non cambiare aspetto tra i fotogrammi in modi che sembrano sbagliati.
Il test di integrità movimento garantisce nessuna distorsione durante movimento veloce. Il video migliorato dovrebbe mantenere movimento naturale, con oggetti che si muovono fluidamente senza distorsione o artefatti durante azione veloce.
Insight di Livello Pro
L'analisi fotogramma di riferimento rivela come l'AI prende in prestito dettaglio da fotogrammi nitidi vicini. Strumenti avanzati analizzano più fotogrammi per trovare la versione più nitida di ogni elemento, poi usano quell'informazione per migliorare altri fotogrammi. Questo crea miglioramento più accurato dell'elaborare ogni fotogramma indipendentemente.
Evitare over-cooking significa miglioramento sottile batte ricostruzione aggressiva. I migliori risultati vengono da miglioramento moderato che migliora qualità senza introdurre artefatti. Elaborazione aggressiva potrebbe creare più dettaglio, ma spesso sembra artificiale e riduce qualità complessiva.
Verifica realtà hardware: strumenti locali richiedono GPU potenti, mentre piattaforme cloud rimuovono questa barriera completamente. Software desktop come Topaz Video AI ha bisogno di serie NVIDIA RTX o GPU Apple Silicon per velocità di elaborazione pratiche. Soluzioni cloud come Video Quality Enhancer eliminano requisiti hardware, rendendo miglioramento professionale accessibile indipendentemente dalla configurazione locale. Se stai lavorando con ChatGPT per guidare il tuo workflow di miglioramento, può aiutarti a scegliere tra approcci locali e cloud basandosi sul tuo hardware.
Verdetto Finale: L'AI Può Davvero Migliorare la Qualità Video?
La risposta è sì, ma con importanti avvertenze che spiegano quando il miglioramento funziona e quando non funziona.
L'AI Non Ripristina Realtà Persa
L'AI non ripristina realtà persa. Invece, ricostruisce dettaglio credibile. Se un video è stato registrato a 480p, non c'è una versione 4K nascosta nei dati. La fotocamera non ha mai catturato quel dettaglio. Il miglioramento AI crea dettaglio plausibile basandosi su dati di addestramento, non informazioni recuperate.
Questa distinzione conta per comprendere cosa il miglioramento può raggiungere. Il video migliorato rappresenta ciò che l'AI pensa dovrebbe esserci, non necessariamente ciò che è stato effettivamente catturato. Questa è ricostruzione, non ripristino.
Quando Fatto Correttamente, i Risultati Sono Stabili, Naturali e Visivamente Superiori
Quando fatto correttamente, il miglioramento AI produce risultati che sono stabili, naturali e visivamente superiori. Strumenti moderni con coerenza temporale creano miglioramento che sembra buono sia in fotogrammi fermi che durante la riproduzione, mantenendo aspetto naturale per tutto il tempo.
La chiave è usare lo strumento giusto per il tuo materiale sorgente e applicare forza di miglioramento appropriata. Strumenti professionali con analisi temporale corretta producono risultati che sembrano convincenti e naturali, evitando gli artefatti e l'instabilità che affliggono l'elaborazione fotogramma per fotogramma.
Il Miglioramento Video AI Non è Sulla Verità: È Sulla Chiarezza Convincente
Il miglioramento video AI non è sulla verità. È sulla chiarezza convincente. L'obiettivo non è recuperare informazioni perse ma creare risultati che sembrano migliori agli spettatori umani. Se il video migliorato sembra più nitido, più pulito e più naturale, ha raggiunto il suo scopo, anche se il dettaglio è tecnicamente "allucinato".
Questa prospettiva aiuta a stabilire aspettative realistiche. Il miglioramento AI crea risultati credibili, visivamente superiori, non ricostruzioni perfette di informazioni perse. La tecnologia funziona meglio quando il materiale sorgente contiene abbastanza informazioni per riconoscimento accurato dei pattern, permettendo all'AI di generare dettaglio che sembra naturale e convincente.