L'IA peut-elle vraiment améliorer la qualité vidéo ?

La question "L'IA peut-elle vraiment améliorer la qualité vidéo ?" a une réponse complexe qui va au-delà d'un simple oui ou non. L'IA moderne ne restaure pas les pixels perdus. Au lieu de cela, elle les remplace par de meilleurs grâce à une reconstruction intelligente. Cette distinction est importante car elle explique pourquoi l'amélioration par IA fonctionne magnifiquement dans certains scénarios tout en échouant dans d'autres, et pourquoi les résultats semblent convaincants même s'ils sont techniquement des détails "hallucinés".
Cet article explore la science derrière l'amélioration vidéo par IA, de la différence fondamentale entre l'amélioration traditionnelle et la super-résolution IA à la percée de la cohérence temporelle qui rend les outils modernes viables. Nous examinerons comment des outils comme Topaz Video AI et les plateformes cloud traitent la vidéo, pourquoi l'amélioration vidéo est plus difficile que l'amélioration d'images, et ce que les benchmarks révèlent sur les résultats réels.
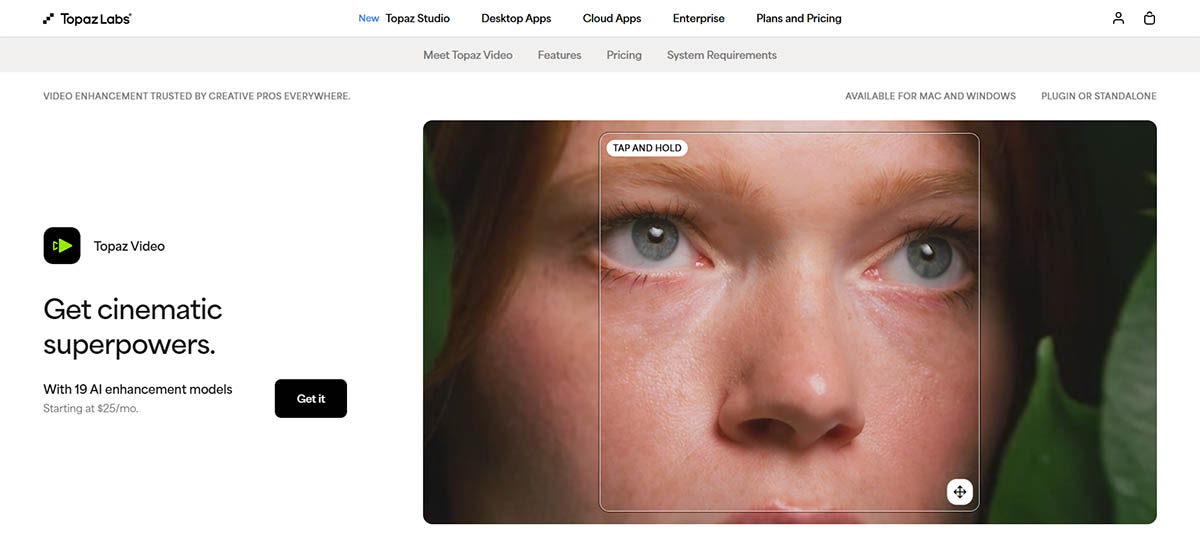
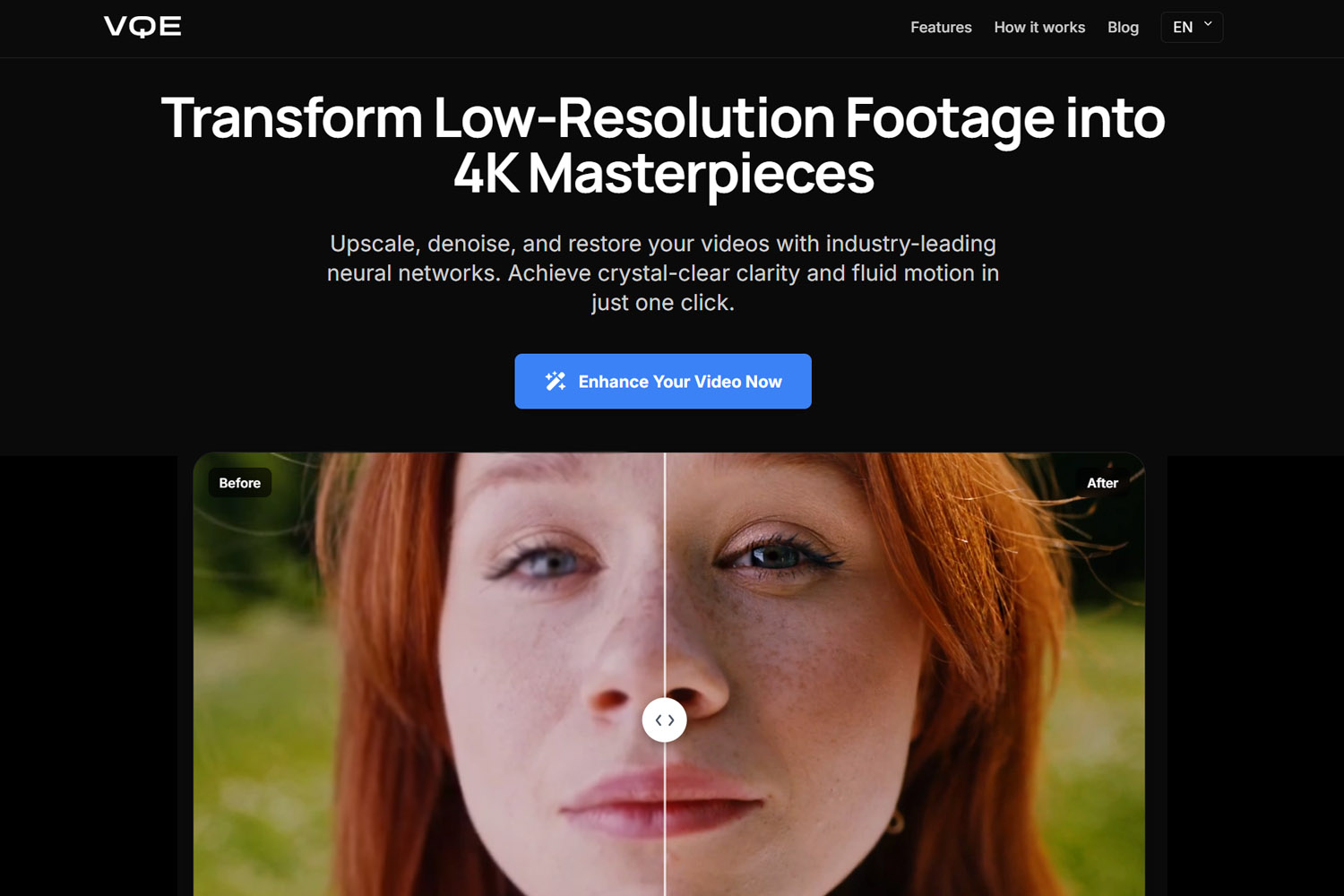
Au-delà du mème CSI "Améliorer"
Le mème "Améliorer !" des séries policières représente un fantasme impossible de 2005 qui est finalement partiellement réalisable en 2026. En 2005, l'interpolation mathématique ne pouvait qu'étirer les pixels existants. Elle ne pouvait pas créer de nouveaux détails. La technologie n'existait tout simplement pas pour reconstruire les informations manquantes de manière convaincante.
L'IA moderne change complètement cette équation. L'IA ne récupère pas les pixels perdus. Au lieu de cela, elle les remplace par de meilleurs basés sur des motifs visuels appris. Lorsque vous donnez une vidéo basse résolution à un améliorateur IA, le réseau neuronal reconnaît les motifs (visages, textures, objets) et génère des détails plausibles qui correspondent aux données d'entraînement haute qualité. Ce n'est pas de la restauration. C'est une reconstruction intelligente.
Le paradoxe des données originales
Le paradoxe fondamental de l'amélioration vidéo : l'amélioration signifie une reconstruction plausible, pas une restauration. Si une vidéo a été enregistrée en 480p, il n'y a pas de version 4K cachée dans les données. La caméra n'a jamais capturé ces détails. Les méthodes d'amélioration traditionnelles reconnaissent cette limitation en étirant simplement les pixels, créant des images plus grandes sans nouvelles informations.
La super-résolution IA fonctionne différemment. Au lieu d'étirer les pixels, l'IA analyse le contenu et génère de nouveaux détails qui ont l'air naturels et convaincants. L'IA reconnaît "c'est un visage" et crée des cils, la texture de la peau et les caractéristiques faciales basées sur la façon dont les visages apparaissent dans les données d'entraînement haute résolution. Le résultat semble considérablement meilleur, mais ce sont des détails reconstruits, pas des informations récupérées.

Cette distinction est importante pour comprendre ce que l'amélioration IA peut et ne peut pas faire. L'IA excelle lorsque le matériel source contient suffisamment d'informations pour une reconnaissance de motifs précise, permettant au réseau neuronal de faire des prédictions éclairées. Lorsque le matériel source est trop dégradé, l'IA a des informations insuffisantes avec lesquelles travailler, conduisant à des artefacts et des résultats peu fiables. Comprendre ce seuil vous aide à décider quand l'amélioration vaut la peine d'être tentée, que vous travailliez avec des séquences floues qui nécessitent un désembuage ou une vidéo basse résolution qui nécessite une amélioration de résolution.
Amélioration traditionnelle vs Super-résolution IA
Comprendre la différence entre l'amélioration traditionnelle et la super-résolution IA explique pourquoi les outils modernes produisent des résultats considérablement meilleurs et quand chaque approche a du sens.
Méthodes traditionnelles : Interpolation bicubique et Lanczos
Les méthodes d'amélioration traditionnelles comme l'interpolation bicubique et Lanczos fonctionnent comme étirer un élastique jusqu'à ce qu'il devienne plus fin. Ces algorithmes utilisent des formules mathématiques pour deviner quels pixels devraient exister entre des points connus, créant une image plus grande en distribuant les informations existantes sur plus de pixels. L'algorithme d'interpolation bicubique utilise des polynômes cubiques pour estimer les valeurs de pixels, tandis que le rééchantillonnage Lanczos applique une fonction sinc fenêtrée pour des résultats plus lisses.
Le processus est simple : si vous avez une image 1080p et voulez 4K, l'algorithme crée quatre pixels à partir de chaque pixel original en utilisant l'interpolation mathématique. Plus de pixels, mais pas de nouvelles informations. Le résultat est plus grand mais pas nécessairement plus net, car vous étalez les mêmes informations limitées sur une toile plus grande.
Cette approche fonctionne de manière acceptable pour de petits facteurs d'amélioration (1,5x ou 2x), mais devient problématique à plus grande échelle. À 4x d'amélioration, les méthodes traditionnelles produisent des résultats flous et doux car il n'y a tout simplement pas assez d'informations source pour créer des détails convaincants uniquement par interpolation mathématique.
Super-résolution IA : Repeindre à partir d'une esquisse floue
La super-résolution IA fonctionne comme repeindre une image détaillée à partir d'une esquisse floue. Au lieu d'étirer les pixels, l'IA analyse les motifs et les textures pour générer de nouveaux détails qui correspondent au type de contenu. Le réseau neuronal reconnaît ce qu'il regarde (visages, bâtiments, nature) et crée des détails plausibles basés sur les données d'entraînement.

La différence clé : la super-résolution IA est basée sur des motifs visuels appris, pas sur l'interpolation mathématique. Lors du traitement d'un visage basse résolution, l'IA n'étire pas simplement les pixels. Au lieu de cela, elle reconnaît la structure faciale et génère des cils, des pores de peau et des détails fins basés sur la façon dont les visages apparaissent dans les données d'entraînement haute résolution.
Cette approche produit des résultats qui semblent considérablement plus naturels que l'amélioration traditionnelle. L'IA génère des détails qui correspondent au type de contenu, créant des textures, des bords et des structures fines qui semblent convaincants aux spectateurs humains. Les détails ne sont pas "réels" au sens d'être récupérés des séquences originales, mais ils sont plausibles et visuellement supérieurs.
Super-résolution : Le terme technique
La super-résolution est le terme technique pour l'amélioration de résolution basée sur l'IA. Elle fait référence au processus d'augmentation de la résolution spatiale au-delà de ce que le capteur original a capturé, en utilisant l'IA pour générer des détails plausibles plutôt que d'étirer simplement les pixels. Cela distingue l'amélioration IA moderne des méthodes d'amélioration traditionnelles.
Comment fonctionnent réellement les outils d'amélioration vidéo IA modernes
L'amélioration vidéo IA en 2026 n'est pas un seul algorithme. Des outils comme Topaz Video AI et Video Quality Enhancer combinent plusieurs systèmes spécialisés travaillant ensemble pour améliorer différents aspects de la qualité vidéo. Comprendre ces composants aide à expliquer pourquoi les outils modernes produisent de meilleurs résultats que les versions antérieures.
Amélioration spatiale : Amélioration de résolution
L'amélioration spatiale augmente la résolution en améliorant depuis des résolutions inférieures (720p, 1080p) vers des résolutions supérieures (1080p, 4K). L'IA reconstruit les détails manquants au lieu d'étirer les pixels, analysant les motifs et les textures pour générer des informations haute résolution plausibles.
Le processus fonctionne en reconnaissant les types de contenu et en générant des détails appropriés. Un visage obtient des caractéristiques faciales, une texture de peau et des détails fins. Un bâtiment obtient des détails architecturaux, des textures et des éléments structurels. L'IA utilise les données d'entraînement pour prédire à quoi ressembleraient les versions haute résolution, créant des résultats qui apparaissent naturels et convaincants.
Cela fonctionne particulièrement bien pour les facteurs d'amélioration de 2x à 4x, où l'IA a suffisamment d'informations source pour faire des prédictions précises. Au-delà de 4x, les résultats deviennent moins fiables car l'IA a des informations insuffisantes avec lesquelles travailler, conduisant à des artefacts et des détails irréalistes.
Amélioration temporelle : Mouvement et interpolation d'images
L'amélioration temporelle améliore la fluidité du mouvement en générant des images intermédiaires, convertissant des séquences 24fps en 60fps ou créant des effets de ralenti. L'IA génère des images intermédiaires tout en préservant le mouvement naturel, analysant les motifs de mouvement pour créer des images intermédiaires réalistes.
Cela fonctionne en comprenant comment les objets se déplacent dans l'espace. L'IA analyse les vecteurs de mouvement entre les images et prédit à quoi devraient ressembler les images intermédiaires, créant un mouvement fluide qui semble naturel plutôt qu'artificiellement interpolé. Le résultat est une lecture fluide qui élimine la saccade dans les séquences à faible fréquence d'images.
L'interpolation d'images est particulièrement efficace pour les mouvements simples et prévisibles comme la marche, la conduite ou le panoramique de caméra. Les scènes complexes avec de nombreux objets qui se chevauchent ou un flou de mouvement rapide peuvent créer des artefacts, mais une amélioration temporelle bien implémentée produit des résultats convaincants.
Réduction de bruit intelligente : Séparer le grain du bruit
La réduction de bruit intelligente distingue le grain de film (bonne texture) du bruit numérique (mauvais artefacts), préservant la texture naturelle tout en supprimant le bruit indésirable. L'IA analyse les motifs sur plusieurs images pour identifier ce qui est du bruit par rapport à ce qui est un vrai détail, permettant une suppression sélective qui maintient la qualité visuelle.

Cela fonctionne car le bruit a des caractéristiques spécifiques : il est aléatoire, change entre les images et apparaît comme du grain ou des taches de couleur. Les vrais détails sont cohérents et suivent des motifs, permettant à l'IA de distinguer entre les deux. En analysant plusieurs images ensemble, l'IA peut supprimer le bruit tout en préservant les textures, les bords et les détails importants.
Le résultat est des séquences plus propres qui maintiennent une apparence naturelle, évitant l'apparence plastique et trop lissée que produisent les méthodes de réduction de bruit traditionnelles. La réduction de bruit IA moderne préserve le grain de film quand c'est approprié tout en supprimant le bruit du capteur et les artefacts de compression.
Récupération et affinement faciaux
La récupération faciale utilise des modèles neuronaux spécialisés entraînés sur la structure faciale pour améliorer les visages tout en maintenant une apparence naturelle. Ces modèles stabilisent les yeux, la texture de la peau et les expressions, prévenant le problème de "peau cireuse" qui afflige les améliorateurs à usage général.

Les outils professionnels utilisent des modèles spécifiques aux visages car les cerveaux humains se concentrent intensément sur les visages. Si les visages ont l'air faux, toute la vidéo semble décalée, même si les arrière-plans sont parfaitement améliorés. Les modèles de récupération faciale reconnaissent l'anatomie faciale et génèrent des détails qui correspondent aux caractéristiques humaines naturelles, maintenant une apparence réaliste tout au long de l'amélioration.
C'est crucial pour les séquences avec des personnes, en particulier les interviews, les portraits ou tout contenu où les visages sont proéminents. Sans récupération faciale spécialisée, les arrière-plans pourraient sembler 4K tandis que les visages restent flous, créant une déconnexion choquante qui fait paraître toute la vidéo pire que l'originale.
IA d'images vs IA vidéo : Pourquoi la vidéo est beaucoup plus difficile
L'amélioration vidéo est fondamentalement plus complexe que l'amélioration d'images car la vidéo nécessite une cohérence temporelle. Les détails doivent rester stables entre les images, pas seulement avoir l'air bien dans une seule image fixe.
Pourquoi l'amélioration image par image échoue
Le traitement de chaque image indépendamment cause plusieurs problèmes qui font paraître la vidéo pire que l'originale. Chaque image améliorée indépendamment crée des textures scintillantes, des détails rampants et des visages instables qui sont immédiatement perceptibles pendant la lecture.
Le problème est que le traitement d'image indépendant ne considère pas le contexte. Une texture pourrait sembler nette dans une image mais différente dans la suivante, créant un effet scintillant qui est distrayant et non naturel. Les visages pourraient changer d'apparence entre les images, avec les yeux ou la texture de la peau changeant de manière qui semble fausse.
Ces artefacts sont plus perceptibles que la faible qualité originale, rendant l'amélioration image par image contre-productive. La vidéo pourrait avoir une résolution plus élevée, mais les incohérences temporelles la font paraître pire globalement.
La vraie percée : La cohérence temporelle
Les outils d'amélioration vidéo modernes résolvent cela en analysant plusieurs images ensemble, garantissant que les détails restent stables dans le temps. Les algorithmes de cohérence temporelle analysent l'image actuelle ainsi que plusieurs images avant et après, utilisant des informations des images environnantes pour maintenir la stabilité.
Les détails doivent rester stables dans le temps, pas seulement avoir l'air bien dans une image fixe. C'est pourquoi les outils sérieux comme Topaz Video AI et les plateformes cloud comme Video Quality Enhancer se concentrent fortement sur l'analyse temporelle. Le processus d'amélioration considère toute la séquence, pas seulement les images individuelles.
Cette conscience temporelle prévient le scintillement, le rampement et l'instabilité. Les textures restent cohérentes, les visages restent stables et le mouvement semble naturel car l'IA utilise des informations de plusieurs images pour maintenir la cohérence. Le résultat est une amélioration qui a l'air bien à la fois dans les images fixes et pendant la lecture.
Modèles de diffusion expliqués
Les modèles de diffusion représentent une avancée significative dans l'amélioration vidéo IA, offrant une génération de détails supérieure par rapport aux systèmes basés sur GAN antérieurs.
Ce que sont vraiment les modèles de diffusion
Les modèles de diffusion sont des modèles génératifs entraînés pour prédire des détails visuels plausibles à travers un processus de raffinement itératif. Ils fonctionnent en apprenant à inverser un processus d'ajout de bruit, construisant progressivement des détails à partir d'entrées basse résolution ou bruyantes.
Ces modèles sont extrêmement forts pour générer des textures, des visages et des structures fines car ils sont entraînés sur de vastes ensembles de données d'images et de vidéos haute qualité. Le processus d'entraînement leur apprend à reconnaître les motifs et à générer des détails qui correspondent à l'apparence naturelle, produisant des résultats qui semblent convaincants aux spectateurs humains.
Stable Diffusion : Modèle d'image, pas vidéo natif
Stable Diffusion est un modèle d'image, pas un modèle vidéo natif, ce qui crée des défis lors de son application à l'amélioration vidéo. Lorsqu'il est utilisé pour la vidéo, les modèles de diffusion sont généralement appliqués image par image, puis combinés avec un guidage temporel pour réduire le scintillement.
Cette approche hybride fonctionne mais n'est pas idéale. La diffusion image par image peut créer des incohérences temporelles, nécessitant un traitement supplémentaire pour maintenir la stabilité entre les images. Le guidage temporel aide, mais c'est un contournement pour un modèle qui n'a pas été conçu pour la vidéo.
La pointe 2026 : Pipelines hybrides
Les outils avancés en 2026 utilisent des pipelines hybrides qui combinent la super-résolution vidéo classique avec le raffinement de détails basé sur la diffusion. Cette approche va au-delà des systèmes GAN uniquement plus anciens, exploitant les forces des méthodes classiques et génératives.
L'approche hybride fonctionne en utilisant la super-résolution classique pour l'amélioration de base, puis en appliquant les modèles de diffusion pour le raffinement des détails. Cela produit des résultats qui sont à la fois stables (des méthodes classiques) et détaillés (des modèles de diffusion), créant une amélioration qui semble naturelle et convaincante.
Quand l'IA va trop loin : Le problème de l'apparence "fausse"
L'amélioration IA peut produire des artefacts qui font paraître la vidéo artificielle, en particulier lorsque le traitement est trop agressif ou lorsque le matériel source est trop dégradé.
Modes d'échec courants
L'artefact se produit lorsque l'IA interprète mal les motifs, créant des détails qui ne correspondent pas au contenu. Des briques pourraient apparaître là où il n'y en a pas, des textures de tissu pourraient être générées incorrectement, ou des motifs pourraient être créés qui semblent non naturels.
La peau cireuse se produit lorsque l'IA supprime les pores et la texture naturels, créant une apparence plastique qui est immédiatement perceptible. Cela se produit lorsque les algorithmes d'amélioration lissent trop agressivement, supprimant les fines variations qui font paraître la peau réelle.
La sur-netteté crée des détails qui ont l'air peints, avec des bords trop nets et des textures qui semblent artificielles. Les détails pourraient être techniquement "corrects" mais ne correspondent pas à l'apparence naturelle, créant un effet de vallée dérangeante.
La solution moderne : Amélioration contrôlée
Les outils professionnels abordent ces problèmes grâce à une force d'amélioration contrôlée et à la préservation du grain de film. L'amélioration contrôlée permet aux utilisateurs d'ajuster l'intensité du traitement, trouvant l'équilibre entre l'amélioration et l'apparence naturelle.
La préservation ou la réinjection du grain de film maintient la texture naturelle qui pourrait être perdue pendant le traitement. Certains outils peuvent analyser et préserver le grain original, ou ajouter du grain synthétique après l'amélioration, maintenant l'apparence naturelle que les spectateurs attendent.
Les outils professionnels exposent des contrôles de réglage pour éviter le sur-traitement, donnant aux utilisateurs le contrôle sur les paramètres d'amélioration. Cela permet un réglage fin qui produit des résultats naturels plutôt qu'une amélioration à l'apparence artificielle.
Benchmarks réels : Ce que différents outils peuvent atteindre
Comprendre ce que différents outils peuvent réellement atteindre aide à fixer des attentes réalistes et à choisir la bonne approche pour votre séquence.
Sources de faible qualité : VHS, MiniDV, 480p
Les sources de faible qualité montrent une grande amélioration perceptuelle lorsqu'elles sont améliorées avec des outils IA modernes. Les cassettes VHS, les séquences MiniDV et les vidéos 480p peuvent être améliorées jusqu'à 1080p ou 4K avec des résultats qui semblent considérablement meilleurs que l'original.
Les résultats sont toujours stylisés, pas magiquement modernes. Les séquences améliorées maintiennent le caractère de l'original tout en paraissant considérablement plus nettes et plus propres. L'IA ne peut pas complètement éliminer les limitations du matériel source, mais elle peut créer des résultats qui sont visuellement supérieurs et plus regardables.
Cela fonctionne mieux lorsque le matériel source a des artefacts de compression minimaux et une mise au point raisonnable. Les séquences fortement dégradées avec une compression sévère ou un flou de mouvement produiront des résultats moins impressionnants, mais même dans ces cas, les outils modernes peuvent créer une amélioration notable. Lorsqu'on traite des séquences floues, comprendre le type de flou aide à déterminer si l'amélioration sera efficace.
Sources de qualité moyenne : Smartphones 1080p, DSLR
Les sources de qualité moyenne atteignent une qualité perceptuelle 4K quasi-native lorsqu'elles sont améliorées avec des outils professionnels. Les séquences de smartphones modernes et les vidéos DSLR enregistrées en 1080p peuvent être améliorées jusqu'à 4K avec des résultats qui semblent presque aussi bons que les séquences 4K natives.
C'est là que des outils comme Topaz Video AI et Video Quality Enhancer brillent le plus. Le matériel source contient suffisamment d'informations pour des prédictions IA précises, permettant aux outils de générer des détails qui semblent naturels et convaincants. Les séquences améliorées maintiennent le caractère de l'original tout en atteignant une résolution plus élevée et une qualité perceptuelle.
La clé est de commencer avec un matériel source décent. Une vidéo 1080p enregistrée à débit binaire élevé s'améliorera mieux qu'une vidéo 1080p enregistrée à débit binaire faible, car le débit binaire plus élevé préserve plus d'informations pour que l'IA travaille.
Métriques vs Vision humaine : Pourquoi "a l'air mieux" compte
La vidéo améliorée par IA peut avoir des scores plus bas sur les métriques techniques comme VMAF tout en paraissant considérablement meilleure aux spectateurs humains. Ce paradoxe révèle pourquoi la qualité perceptuelle compte plus que la précision au niveau des pixels.
Le paradoxe de la précision
La vidéo améliorée par IA peut avoir des scores plus bas sur des métriques comme VMAF car le processus d'amélioration crée des détails qui n'étaient pas dans l'original. Les métriques techniques mesurent la précision par rapport à la source, mais l'amélioration IA crée intentionnellement de nouveaux détails, ce qui peut abaisser les scores de précision. La métrique VMAF (Video Multi-method Assessment Fusion) développée par Netflix combine plusieurs mesures de qualité pour prédire la perception humaine, mais elle mesure la fidélité à la source plutôt que l'amélioration perceptuelle.
Pourtant, la vidéo améliorée semble considérablement meilleure aux spectateurs humains, qui se soucient plus de la clarté, des visages et de la stabilité du mouvement que de la précision au niveau des pixels. Cela crée une situation où les métriques techniques suggèrent une qualité inférieure, mais la perception humaine indique une qualité supérieure.
Pourquoi cela se produit
L'IA privilégie la qualité perceptuelle, pas la précision au niveau des pixels. Le processus d'amélioration est conçu pour créer des résultats qui ont l'air bien aux humains, pas pour correspondre à l'original pixel par pixel. Cela signifie que l'IA pourrait générer des détails qui améliorent la qualité perceptuelle même si cela réduit la précision technique.
Les humains se soucient plus de la clarté, des visages et de la stabilité du mouvement que de savoir si chaque pixel correspond à l'original. Si un visage semble plus net et plus naturel, les spectateurs perçoivent une qualité supérieure même si la version améliorée ne correspond pas à l'original pixel par pixel. Si vous n'êtes pas sûr si votre séquence est adaptée à l'amélioration, ChatGPT peut aider à analyser la qualité de votre vidéo et recommander la bonne approche.
Cette distinction est importante pour comprendre les résultats d'amélioration. Les métriques techniques fournissent une perspective, mais la perception humaine en fournit une autre, et pour l'amélioration vidéo, la perception humaine est ce qui compte finalement.
Comment savoir si un outil d'amélioration vidéo est vraiment bon
La plupart des critiques se concentrent sur la qualité de sortie mais ignorent les facteurs critiques qui déterminent si l'amélioration améliore réellement la vidéo ou introduit de nouveaux problèmes.
Les tests que la plupart des critiques ignorent
Le test de scintillement temporel vérifie si la texture scintille entre les images. Un bon outil d'amélioration maintient des textures stables tout au long de la vidéo, tandis que les mauvais outils créent un scintillement qui est immédiatement perceptible pendant la lecture.
Le test de stabilité faciale vérifie si les yeux et la peau restent cohérents entre les images. Les visages devraient sembler stables et naturels tout au long de la vidéo, ne changeant pas d'apparence entre les images de manière qui semble fausse.
Le test d'intégrité du mouvement garantit qu'il n'y a pas de déformation pendant les mouvements rapides. La vidéo améliorée devrait maintenir un mouvement naturel, avec des objets se déplaçant en douceur sans distorsion ni artefacts pendant l'action rapide.
Insights de niveau professionnel
L'analyse d'image de référence révèle comment l'IA emprunte des détails aux images nettes proches. Les outils avancés analysent plusieurs images pour trouver la version la plus nette de chaque élément, puis utilisent ces informations pour améliorer d'autres images. Cela crée une amélioration plus précise que le traitement de chaque image indépendamment.
Éviter le sur-traitement signifie qu'une amélioration subtile bat une reconstruction agressive. Les meilleurs résultats proviennent d'une amélioration modérée qui améliore la qualité sans introduire d'artefacts. Le traitement agressif pourrait créer plus de détails, mais il a souvent l'air artificiel et réduit la qualité globale.
Vérification de la réalité matérielle : les outils locaux nécessitent des GPU puissants, tandis que les plateformes cloud éliminent complètement cette barrière. Les logiciels de bureau comme Topaz Video AI nécessitent des GPU NVIDIA RTX ou Apple Silicon pour des vitesses de traitement pratiques. Les solutions cloud comme Video Quality Enhancer éliminent les exigences matérielles, rendant l'amélioration professionnelle accessible indépendamment de la configuration locale. Si vous travaillez avec ChatGPT pour guider votre flux de travail d'amélioration, il peut vous aider à choisir entre les approches locales et cloud basées sur votre matériel.
Verdict final : L'IA peut-elle vraiment améliorer la qualité vidéo ?
La réponse est oui, mais avec des mises en garde importantes qui expliquent quand l'amélioration fonctionne et quand elle ne fonctionne pas.
L'IA ne restaure pas la réalité perdue
L'IA ne restaure pas la réalité perdue. Au lieu de cela, elle reconstruit des détails croyables. Si une vidéo a été enregistrée en 480p, il n'y a pas de version 4K cachée dans les données. La caméra n'a jamais capturé ces détails. L'amélioration IA crée des détails plausibles basés sur les données d'entraînement, pas des informations récupérées.
Cette distinction est importante pour comprendre ce que l'amélioration peut atteindre. La vidéo améliorée représente ce que l'IA pense devrait être là, pas nécessairement ce qui a été réellement capturé. C'est de la reconstruction, pas de la restauration.
Quand c'est fait correctement, les résultats sont stables, naturels et visuellement supérieurs
Quand c'est fait correctement, l'amélioration IA produit des résultats qui sont stables, naturels et visuellement supérieurs. Les outils modernes avec cohérence temporelle créent une amélioration qui a l'air bien à la fois dans les images fixes et pendant la lecture, maintenant une apparence naturelle tout au long.
La clé est d'utiliser le bon outil pour votre matériel source et d'appliquer une force d'amélioration appropriée. Les outils professionnels avec une analyse temporelle appropriée produisent des résultats qui semblent convaincants et naturels, évitant les artefacts et l'instabilité qui affligent le traitement image par image.
L'amélioration vidéo IA n'est pas une question de vérité : C'est une question de clarté convaincante
L'amélioration vidéo IA n'est pas une question de vérité. C'est une question de clarté convaincante. L'objectif n'est pas de récupérer les informations perdues mais de créer des résultats qui ont l'air mieux aux spectateurs humains. Si la vidéo améliorée semble plus nette, plus propre et plus naturelle, elle a atteint son objectif, même si les détails sont techniquement "hallucinés".
Cette perspective aide à fixer des attentes réalistes. L'amélioration IA crée des résultats croyables et visuellement supérieurs, pas des reconstructions parfaites d'informations perdues. La technologie fonctionne mieux lorsque le matériel source contient suffisamment d'informations pour une reconnaissance de motifs précise, permettant à l'IA de générer des détails qui semblent naturels et convaincants.