¿Puede la IA Realmente Mejorar la Calidad de Video?

La pregunta "¿Puede la IA realmente mejorar la calidad de video?" tiene una respuesta compleja que va más allá de un simple sí o no. La IA moderna no restaura píxeles perdidos. En cambio, los reemplaza con mejores a través de reconstrucción inteligente. Esta distinción importa porque explica por qué la mejora con IA funciona maravillosamente en algunos escenarios mientras falla en otros, y por qué los resultados se ven convincentes aunque técnicamente sean detalle "alucinado".
Este artículo explora la ciencia detrás de la mejora de video con IA, desde la diferencia fundamental entre aumento de resolución tradicional y super-resolución con IA hasta el avance de la consistencia temporal que hace viables las herramientas modernas. Examinaremos cómo herramientas como Topaz Video AI y plataformas en la nube procesan video, por qué la mejora de video es más difícil que la mejora de imágenes, y qué revelan los puntos de referencia sobre resultados del mundo real.
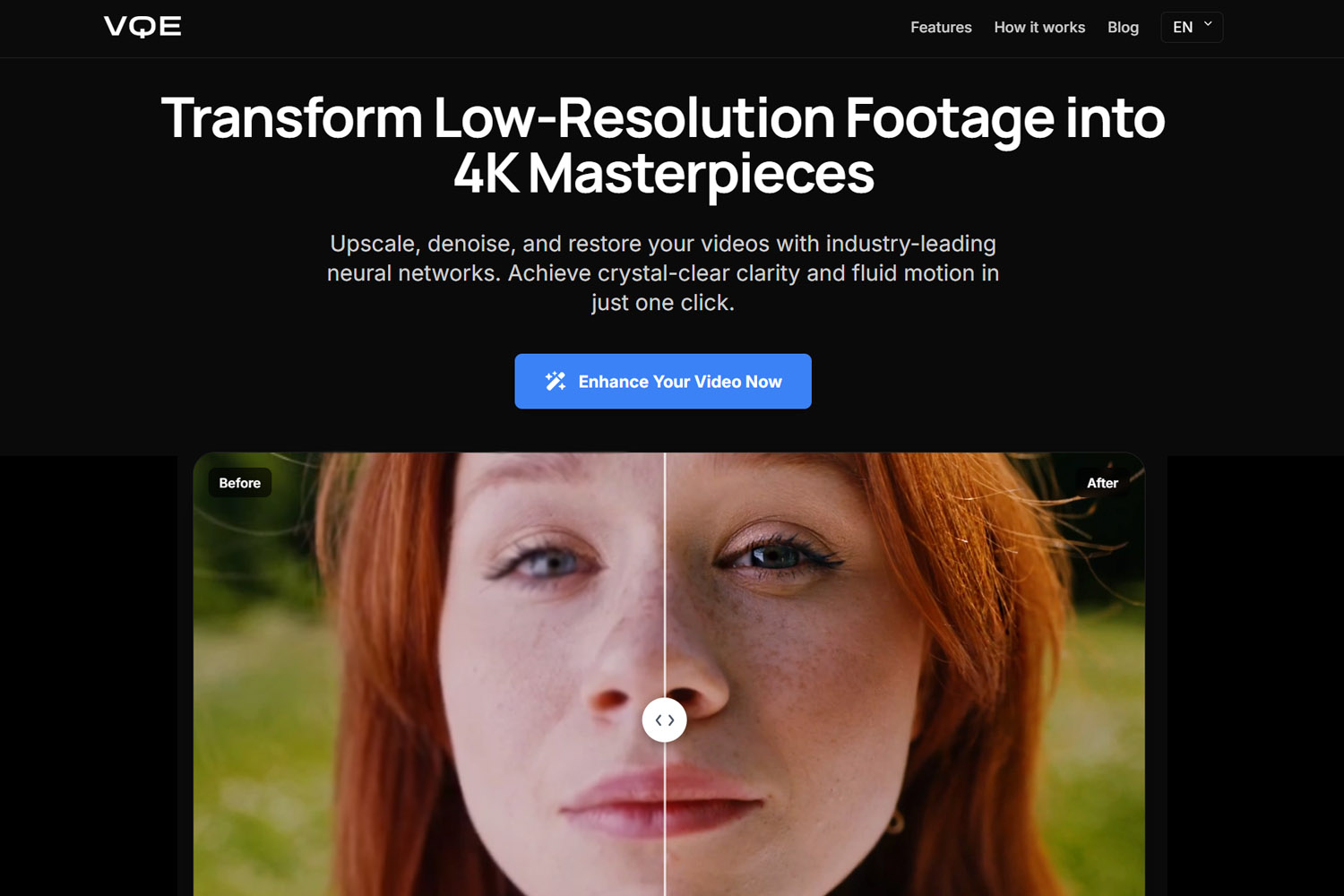
Más Allá del Meme "Mejorar" de CSI
El meme "¡Mejorar!" de programas de crímenes representa una fantasía imposible de 2005 que finalmente es parcialmente alcanzable en 2026. En 2005, la interpolación matemática solo podía estirar píxeles existentes. No podía crear nuevo detalle. La tecnología simplemente no existía para reconstruir información faltante de manera convincente.
La IA moderna cambia esta ecuación completamente. La IA no recupera píxeles perdidos. En cambio, los reemplaza con mejores basados en patrones visuales aprendidos. Cuando alimentas un video de baja resolución a un mejorador de IA, la red neuronal reconoce patrones (rostros, texturas, objetos) y genera detalle plausible que coincide con datos de entrenamiento de alta calidad. Esto no es restauración. Es reconstrucción inteligente.
La Paradoja de los Datos Originales
La paradoja fundamental de la mejora de video: la mejora significa reconstrucción plausible, no restauración. Si un video fue grabado a 480p, no hay una versión 4K oculta en los datos. La cámara nunca capturó ese detalle. Los métodos tradicionales de aumento de resolución reconocen esta limitación simplemente estirando píxeles, creando imágenes más grandes sin nueva información.
La super-resolución con IA funciona de manera diferente. En lugar de estirar píxeles, la IA analiza el contenido y genera nuevo detalle que se ve natural y convincente. La IA reconoce "esto es un rostro" y crea pestañas, textura de piel y características faciales basadas en cómo aparecen los rostros en datos de entrenamiento de alta resolución. El resultado se ve dramáticamente mejor, pero es detalle reconstruido, no información recuperada.

Esta distinción importa para entender lo que la mejora con IA puede y no puede hacer. La IA sobresale cuando el material fuente contiene suficiente información para reconocimiento preciso de patrones, permitiendo que la red neuronal haga predicciones educadas. Cuando el material fuente está demasiado degradado, la IA tiene información insuficiente con la que trabajar, llevando a artefactos y resultados poco confiables. Entender este umbral te ayuda a decidir cuándo vale la pena intentar la mejora, ya sea que estés trabajando con material borroso que necesita desenfoque o video de baja resolución que necesita aumento de resolución.
Aumento de Resolución Tradicional vs Super-Resolución con IA
Entender la diferencia entre aumento de resolución tradicional y super-resolución con IA explica por qué las herramientas modernas producen resultados dramáticamente mejores y cuándo cada enfoque tiene sentido.
Métodos Tradicionales: Interpolación Bicúbica y Lanczos
Los métodos tradicionales de aumento de resolución como la interpolación bicúbica y Lanczos funcionan como estirar una banda elástica hasta que se vuelve más delgada. Estos algoritmos usan fórmulas matemáticas para adivinar qué píxeles deberían existir entre puntos conocidos, creando una imagen más grande distribuyendo información existente a través de más píxeles. El algoritmo de interpolación bicúbica usa polinomios cúbicos para estimar valores de píxeles, mientras que el remuestreo de Lanczos aplica una función sinc con ventana para resultados más suaves.
El proceso es directo: si tienes una imagen de 1080p y quieres 4K, el algoritmo crea cuatro píxeles de cada píxel original usando interpolación matemática. Más píxeles, pero sin nueva información. El resultado es más grande pero no necesariamente más nítido, porque estás extendiendo la misma información limitada a través de un lienzo más grande.
Este enfoque funciona aceptablemente para factores de aumento de resolución pequeños (1.5x o 2x), pero se vuelve problemático a escalas mayores. A aumento de resolución de 4x, los métodos tradicionales producen resultados borrosos y suaves porque simplemente no hay suficiente información fuente para crear detalle convincente solo a través de interpolación matemática.
Super-Resolución con IA: Repintar desde un Boceto Borroso
La super-resolución con IA funciona como repintar una imagen detallada desde un boceto borroso. En lugar de estirar píxeles, la IA analiza patrones y texturas para generar nuevo detalle que se ajusta al tipo de contenido. La red neuronal reconoce lo que está viendo (rostros, edificios, naturaleza) y crea detalle plausible basado en datos de entrenamiento.

La diferencia clave: la super-resolución con IA se basa en patrones visuales aprendidos, no en interpolación matemática. Al procesar un rostro de baja resolución, la IA no solo estira píxeles. En cambio, reconoce la estructura facial y genera pestañas, poros de piel y detalles finos basados en cómo aparecen los rostros en datos de entrenamiento de alta resolución.
Este enfoque produce resultados que se ven dramáticamente más naturales que el aumento de resolución tradicional. La IA genera detalle que coincide con el tipo de contenido, creando texturas, bordes y estructuras finas que se ven convincentes para los espectadores humanos. El detalle no es "real" en el sentido de ser recuperado del material original, pero es plausible y visualmente superior.
Super-Resolución: El Término Técnico
Super-resolución es el término técnico para mejora de resolución basada en IA. Se refiere al proceso de aumentar la resolución espacial más allá de lo que el sensor original capturó, usando IA para generar detalle plausible en lugar de simplemente estirar píxeles. Esto distingue la mejora de IA moderna de los métodos tradicionales de aumento de resolución.
Cómo Funcionan Realmente las Herramientas Modernas de Mejora de Video con IA
La mejora de video con IA en 2026 no es un solo algoritmo. Herramientas como Topaz Video AI y Video Quality Enhancer combinan múltiples sistemas especializados trabajando juntos para mejorar diferentes aspectos de la calidad de video. Entender estos componentes ayuda a explicar por qué las herramientas modernas producen mejores resultados que versiones anteriores.
Mejora Espacial: Aumento de Resolución
La mejora espacial aumenta la resolución aumentando la resolución de resoluciones más bajas (720p, 1080p) a más altas (1080p, 4K). La IA reconstruye detalle faltante en lugar de estirar píxeles, analizando patrones y texturas para generar información de alta resolución plausible.
El proceso funciona reconociendo tipos de contenido y generando detalle apropiado. Un rostro obtiene características faciales, textura de piel y detalles finos. Un edificio obtiene detalles arquitectónicos, texturas y elementos estructurales. La IA usa datos de entrenamiento para predecir cómo se verían las versiones de mayor resolución, creando resultados que aparecen naturales y convincentes.
Esto funciona particularmente bien para factores de aumento de resolución de 2x a 4x, donde la IA tiene suficiente información fuente para hacer predicciones precisas. Más allá de 4x, los resultados se vuelven menos confiables porque la IA tiene información insuficiente con la que trabajar, llevando a artefactos y detalle poco realista.
Mejora Temporal: Movimiento e Interpolación de Fotogramas
La mejora temporal mejora la suavidad del movimiento generando fotogramas intermedios, convirtiendo material de 24fps a 60fps o creando efectos de cámara lenta. La IA genera fotogramas intermedios mientras preserva movimiento natural, analizando patrones de movimiento para crear fotogramas intermedios realistas.
Esto funciona entendiendo cómo se mueven los objetos a través del espacio. La IA analiza vectores de movimiento entre fotogramas y predice cómo deberían verse los fotogramas intermedios, creando movimiento suave que se ve natural en lugar de interpolado artificialmente. El resultado es reproducción fluida que elimina la falta de fluidez en material de baja velocidad de fotogramas.
La interpolación de fotogramas es particularmente efectiva para movimiento simple y predecible como caminar, conducir o paneo de cámara. Escenas complejas con muchos objetos superpuestos o desenfoque de movimiento rápido pueden crear artefactos, pero la mejora temporal bien implementada produce resultados convincentes.
Eliminación de Ruido Inteligente: Separando Grano de Ruido
La eliminación de ruido inteligente distingue entre grano de película (buena textura) y ruido digital (artefactos malos), preservando textura natural mientras elimina ruido no deseado. La IA analiza patrones a través de múltiples fotogramas para identificar qué es ruido versus qué es detalle real, permitiendo eliminación selectiva que mantiene calidad visual.

Esto funciona porque el ruido tiene características específicas: es aleatorio, cambia entre fotogramas y aparece como grano o motas de color. El detalle real es consistente y sigue patrones, permitiendo que la IA distinga entre los dos. Al analizar múltiples fotogramas juntos, la IA puede eliminar ruido mientras preserva texturas, bordes y detalles importantes.
El resultado es material más limpio que mantiene apariencia natural, evitando la apariencia plástica y sobre-suavizada que producen los métodos tradicionales de eliminación de ruido. La eliminación de ruido con IA moderna preserva el grano de película cuando es apropiado mientras elimina ruido del sensor y artefactos de compresión.
Recuperación y Refinamiento Facial
La recuperación facial usa modelos neuronales especializados entrenados en estructura facial para mejorar rostros mientras mantiene apariencia natural. Estos modelos estabilizan ojos, textura de piel y expresiones, previniendo el problema de "piel cerosa" que plaga los aumentadores de resolución de propósito general.

Las herramientas profesionales usan modelos específicos para rostros porque los cerebros humanos se enfocan intensamente en los rostros. Si los rostros se ven mal, todo el video se siente mal, incluso si los fondos están perfectamente mejorados. Los modelos de recuperación facial reconocen la anatomía facial y generan detalle que coincide con características humanas naturales, manteniendo apariencia realista a lo largo de la mejora.
Esto es crucial para material con personas, especialmente entrevistas, retratos o cualquier contenido donde los rostros son prominentes. Sin recuperación facial especializada, los fondos podrían verse en 4K mientras los rostros permanecen borrosos, creando una desconexión discordante que hace que todo el video se vea peor que el original.
IA de Imagen vs IA de Video: Por Qué el Video es Mucho Más Difícil
Mejorar video es fundamentalmente más complejo que mejorar imágenes porque el video requiere consistencia temporal. El detalle debe permanecer estable entre fotogramas, no solo verse bien en una sola imagen estática.
Por Qué Falla la Mejora Fotograma por Fotograma
Procesar cada fotograma independientemente causa varios problemas que hacen que el video se vea peor que el original. Cada fotograma mejorado independientemente crea texturas parpadeantes, detalle que se arrastra y rostros inestables que son inmediatamente notables durante la reproducción.
El problema es que el procesamiento de fotogramas independiente no considera el contexto. Una textura podría verse nítida en un fotograma pero diferente en el siguiente, creando un efecto brillante que es distractor y antinatural. Los rostros podrían cambiar apariencia entre fotogramas, con ojos o textura de piel cambiando de maneras que se ven mal.
Estos artefactos son más notables que la baja calidad original, haciendo que la mejora fotograma por fotograma sea contraproducente. El video podría tener mayor resolución, pero las inconsistencias temporales lo hacen verse peor en general.
El Verdadero Avance: Consistencia Temporal
Las herramientas modernas de mejora de video resuelven esto analizando múltiples fotogramas juntos, asegurando que el detalle permanezca estable a lo largo del tiempo. Los algoritmos de consistencia temporal analizan el fotograma actual junto con varios fotogramas antes y después, usando información de fotogramas circundantes para mantener estabilidad.
El detalle debe permanecer estable a lo largo del tiempo, no solo verse bien en una imagen estática. Esta es la razón por la que herramientas serias como Topaz Video AI y plataformas en la nube como Video Quality Enhancer se enfocan fuertemente en análisis temporal. El proceso de mejora considera toda la secuencia, no solo fotogramas individuales.
Esta conciencia temporal previene parpadeos, arrastres e inestabilidad. Las texturas permanecen consistentes, los rostros se mantienen estables y el movimiento se ve natural porque la IA usa información de múltiples fotogramas para mantener coherencia. El resultado es mejora que se ve bien tanto en fotogramas estáticos como durante la reproducción.
Modelos de Difusión Explicados
Los modelos de difusión representan un avance significativo en la mejora de video con IA, ofreciendo generación de detalle superior comparada con sistemas anteriores basados en GAN.
Qué Son Realmente los Modelos de Difusión
Los modelos de difusión son modelos generativos entrenados para predecir detalle visual plausible a través de un proceso de refinamiento iterativo. Funcionan aprendiendo a revertir un proceso de agregar ruido, construyendo gradualmente detalle desde entradas de baja resolución o ruidosas.
Estos modelos son extremadamente fuertes generando texturas, rostros y estructuras finas porque están entrenados en vastos conjuntos de datos de imágenes y video de alta calidad. El proceso de entrenamiento les enseña a reconocer patrones y generar detalle que coincide con apariencia natural, produciendo resultados que se ven convincentes para los espectadores humanos.
Stable Diffusion: Modelo de Imagen, No Video Nativo
Stable Diffusion es un modelo de imagen, no un modelo de video nativo, lo que crea desafíos al aplicarlo a la mejora de video. Cuando se usa para video, los modelos de difusión típicamente se aplican fotograma por fotograma, luego se combinan con guía temporal para reducir parpadeos.
Este enfoque híbrido funciona pero no es ideal. La difusión fotograma por fotograma puede crear inconsistencias temporales, requiriendo procesamiento adicional para mantener estabilidad entre fotogramas. La guía temporal ayuda, pero es una solución para un modelo que no fue diseñado para video.
La Vanguardia 2026: Pipelines Híbridos
Las herramientas avanzadas en 2026 usan pipelines híbridos que combinan super-resolución de video clásica con refinamiento de detalle basado en difusión. Este enfoque va más allá de sistemas anteriores solo GAN, aprovechando las fortalezas de ambos métodos clásicos y generativos.
El enfoque híbrido funciona usando super-resolución clásica para mejora base, luego aplicando modelos de difusión para refinamiento de detalle. Esto produce resultados que son tanto estables (de métodos clásicos) como detallados (de modelos de difusión), creando mejora que se ve natural y convincente.
Cuando la IA Va Demasiado Lejos: El Problema de la Apariencia "Falsa"
La mejora con IA puede producir artefactos que hacen que el video se vea artificial, particularmente cuando el procesamiento es demasiado agresivo o cuando el material fuente está demasiado degradado.
Modos de Falla Comunes
Los artefactos ocurren cuando la IA malinterpreta patrones, creando detalle que no coincide con el contenido. Podrían aparecer ladrillos donde no los hay, las texturas de tela podrían generarse incorrectamente, o podrían crearse patrones que se ven antinaturales.
La piel cerosa ocurre cuando la IA elimina poros y textura naturales, creando una apariencia plástica que es inmediatamente notable. Esto ocurre cuando los algoritmos de mejora suavizan demasiado agresivamente, eliminando las variaciones finas que hacen que la piel se vea real.
El sobre-enfoque crea detalle que se ve pintado, con bordes que son demasiado nítidos y texturas que aparecen artificiales. El detalle podría ser técnicamente "correcto" pero no coincide con apariencia natural, creando un efecto de valle inquietante.
La Solución Moderna: Mejora Controlada
Las herramientas profesionales abordan estos problemas a través de fuerza de mejora controlada y preservación de grano de película. La mejora controlada permite a los usuarios ajustar la intensidad del procesamiento, encontrando el equilibrio entre mejora y apariencia natural.
La preservación o re-inyección de grano de película mantiene textura natural que podría perderse durante el procesamiento. Algunas herramientas pueden analizar y preservar grano original, o agregar grano sintético después de la mejora, manteniendo la apariencia natural que los espectadores esperan.
Las herramientas profesionales exponen controles de ajuste para evitar sobre-procesamiento, dando a los usuarios control sobre parámetros de mejora. Esto permite ajuste fino que produce resultados naturales en lugar de mejora de apariencia artificial.
Puntos de Referencia del Mundo Real: Lo que Diferentes Herramientas Pueden Lograr
Entender lo que diferentes herramientas realmente pueden lograr ayuda a establecer expectativas realistas y elegir el enfoque correcto para tu material.
Fuentes de Baja Calidad: VHS, MiniDV, 480p
Las fuentes de baja calidad muestran gran mejora perceptual cuando se mejoran con herramientas modernas de IA. Las cintas VHS, material MiniDV y videos de 480p pueden aumentarse a 1080p o 4K con resultados que se ven dramáticamente mejores que el original.
Los resultados siguen siendo estilizados, no mágicamente modernos. El material mejorado mantiene el carácter del original mientras se ve significativamente más nítido y limpio. La IA no puede eliminar completamente las limitaciones del material fuente, pero puede crear resultados que son visualmente superiores y más viables.
Esto funciona mejor cuando el material fuente tiene artefactos de compresión mínimos y enfoque razonable. El material fuertemente degradado con compresión severa o desenfoque de movimiento producirá resultados menos impresionantes, pero incluso en estos casos, las herramientas modernas pueden crear mejora notable. Al lidiar con material borroso, entender el tipo de desenfoque ayuda a determinar si la mejora será efectiva.
Fuentes de Calidad Media: Smartphones 1080p, DSLRs
Las fuentes de calidad media logran calidad perceptual casi nativa 4K cuando se mejoran con herramientas profesionales. El material de smartphones modernos y video DSLR grabado a 1080p puede aumentarse a 4K con resultados que se ven casi tan buenos como material 4K nativo.
Aquí es donde herramientas como Topaz Video AI y Video Quality Enhancer brillan más. El material fuente contiene suficiente información para predicciones precisas de IA, permitiendo que las herramientas generen detalle que se ve natural y convincente. El material mejorado mantiene el carácter del original mientras logra mayor resolución y calidad percibida.
La clave es comenzar con material fuente decente. Un video de 1080p grabado a alto bitrate aumentará mejor que un video de 1080p grabado a bajo bitrate, porque el bitrate más alto preserva más información para que la IA trabaje.
Métricas vs Visión Humana: Por Qué "Se Ve Mejor" Importa
El video mejorado con IA puede puntuar más bajo en métricas técnicas como VMAF mientras se ve dramáticamente mejor para los espectadores humanos. Esta paradoja revela por qué la calidad perceptual importa más que la precisión a nivel de píxel.
La Paradoja de la Precisión
El video mejorado con IA puede puntuar más bajo en métricas como VMAF porque el proceso de mejora crea detalle que no estaba en el original. Las métricas técnicas miden precisión a la fuente, pero la mejora con IA intencionalmente crea nuevo detalle, lo que puede bajar las puntuaciones de precisión. La métrica VMAF (Video Multi-method Assessment Fusion) desarrollada por Netflix combina múltiples mediciones de calidad para predecir percepción humana, pero mide fidelidad a la fuente en lugar de mejora perceptual.
Sin embargo, el video mejorado se ve dramáticamente mejor para los espectadores humanos, que se preocupan más por claridad, rostros y estabilidad de movimiento que por precisión a nivel de píxel. Esto crea una situación donde las métricas técnicas sugieren menor calidad, pero la percepción humana indica mayor calidad.
Por Qué Esto Sucede
La IA prioriza calidad perceptual, no precisión a nivel de píxel. El proceso de mejora está diseñado para crear resultados que se ven bien para los humanos, no para coincidir con el original píxel por píxel. Esto significa que la IA podría generar detalle que mejora la calidad percibida incluso si reduce la precisión técnica.
Los humanos se preocupan más por claridad, rostros y estabilidad de movimiento que por si cada píxel coincide con el original. Si un rostro se ve más nítido y natural, los espectadores perciben mayor calidad incluso si la versión mejorada no coincide con el original píxel por píxel. Si no estás seguro de si tu material es adecuado para mejora, ChatGPT puede ayudar a analizar la calidad de tu video y recomendar el enfoque correcto.
Esta distinción importa para entender los resultados de mejora. Las métricas técnicas proporcionan una perspectiva, pero la percepción humana proporciona otra, y para la mejora de video, la percepción humana es lo que finalmente importa.
Cómo Saber Si una Herramienta de Mejora de Video es Realmente Buena
La mayoría de las reseñas se enfocan en la calidad de salida pero ignoran factores críticos que determinan si la mejora realmente mejora el video o introduce nuevos problemas.
Las Pruebas que la Mayoría de las Reseñas Ignoran
Las pruebas de parpadeo temporal verifican si la textura brilla entre fotogramas. Una buena herramienta de mejora mantiene texturas estables a lo largo del video, mientras que herramientas pobres crean parpadeos que son inmediatamente notables durante la reproducción.
Las pruebas de estabilidad facial verifican si los ojos y la piel permanecen consistentes entre fotogramas. Los rostros deberían verse estables y naturales a lo largo del video, no cambiando apariencia entre fotogramas de maneras que se ven mal.
Las pruebas de integridad de movimiento aseguran que no haya deformación durante movimiento rápido. El video mejorado debería mantener movimiento natural, con objetos moviéndose suavemente sin distorsión o artefactos durante acción rápida.
Perspectivas de Nivel Profesional
El análisis de fotograma de referencia revela cómo la IA toma prestado detalle de fotogramas nítidos cercanos. Las herramientas avanzadas analizan múltiples fotogramas para encontrar la versión más nítida de cada elemento, luego usan esa información para mejorar otros fotogramas. Esto crea mejora más precisa que procesar cada fotograma independientemente.
Evitar sobre-cocinar significa que la mejora sutil vence a la reconstrucción agresiva. Los mejores resultados provienen de mejora moderada que mejora la calidad sin introducir artefactos. El procesamiento agresivo podría crear más detalle, pero a menudo se ve artificial y reduce la calidad general.
Verificación de realidad de hardware: las herramientas locales requieren GPUs potentes, mientras que las plataformas en la nube eliminan esta barrera completamente. El software de escritorio como Topaz Video AI necesita GPUs serie NVIDIA RTX o Apple Silicon para velocidades de procesamiento prácticas. Las soluciones en la nube como Video Quality Enhancer eliminan los requisitos de hardware, haciendo que la mejora profesional sea accesible independientemente de la configuración local. Si estás trabajando con ChatGPT para guiar tu flujo de trabajo de mejora, puede ayudarte a elegir entre enfoques locales y en la nube basados en tu hardware.
Veredicto Final: ¿Puede la IA Realmente Mejorar la Calidad de Video?
La respuesta es sí, pero con advertencias importantes que explican cuándo la mejora funciona y cuándo no.
La IA No Restaura la Realidad Perdida
La IA no restaura la realidad perdida. En cambio, reconstruye detalle creíble. Si un video fue grabado a 480p, no hay una versión 4K oculta en los datos. La cámara nunca capturó ese detalle. La mejora con IA crea detalle plausible basado en datos de entrenamiento, no información recuperada.
Esta distinción importa para entender lo que la mejora puede lograr. El video mejorado representa lo que la IA piensa que debería estar ahí, no necesariamente lo que fue realmente capturado. Esto es reconstrucción, no restauración.
Cuando se Hace Correctamente, los Resultados son Estables, Naturales y Visualmente Superiores
Cuando se hace correctamente, la mejora con IA produce resultados que son estables, naturales y visualmente superiores. Las herramientas modernas con consistencia temporal crean mejora que se ve bien tanto en fotogramas estáticos como durante la reproducción, manteniendo apariencia natural a lo largo.
La clave es usar la herramienta correcta para tu material fuente y aplicar fuerza de mejora apropiada. Las herramientas profesionales con análisis temporal adecuado producen resultados que se ven convincentes y naturales, evitando los artefactos y la inestabilidad que plagan el procesamiento fotograma por fotograma.
La Mejora de Video con IA No se Trata de Verdad: Se Trata de Claridad Convincente
La mejora de video con IA no se trata de verdad. Se trata de claridad convincente. El objetivo no es recuperar información perdida sino crear resultados que se vean mejor para los espectadores humanos. Si el video mejorado se ve más nítido, más limpio y más natural, ha logrado su propósito, incluso si el detalle es técnicamente "alucinado".
Esta perspectiva ayuda a establecer expectativas realistas. La mejora con IA crea resultados creíbles y visualmente superiores, no reconstrucciones perfectas de información perdida. La tecnología funciona mejor cuando el material fuente contiene suficiente información para reconocimiento preciso de patrones, permitiendo que la IA genere detalle que se ve natural y convincente.