Kann KI die Videoqualität wirklich verbessern?

Die Frage "Kann KI die Videoqualität wirklich verbessern?" hat eine komplexe Antwort, die über ein einfaches Ja oder Nein hinausgeht. Moderne KI stellt keine verlorenen Pixel wieder her. Stattdessen ersetzt sie sie durch bessere durch intelligente Rekonstruktion. Diese Unterscheidung ist wichtig, weil sie erklärt, warum KI-Verbesserung in einigen Szenarien wunderbar funktioniert, während sie in anderen versagt, und warum die Ergebnisse überzeugend aussehen, obwohl sie technisch "halluzinierte" Details sind.
Dieser Artikel erforscht die Wissenschaft hinter KI-Videoverbesserung, vom grundlegenden Unterschied zwischen traditionellem Upscaling und KI-Super-Resolution bis zum Durchbruch der zeitlichen Konsistenz, der moderne Tools praktikabel macht. Wir untersuchen, wie Tools wie Topaz Video AI und Cloud-Plattformen Video verarbeiten, warum Videoverbesserung schwieriger ist als Bildverbesserung und was Benchmarks über reale Ergebnisse offenbaren.
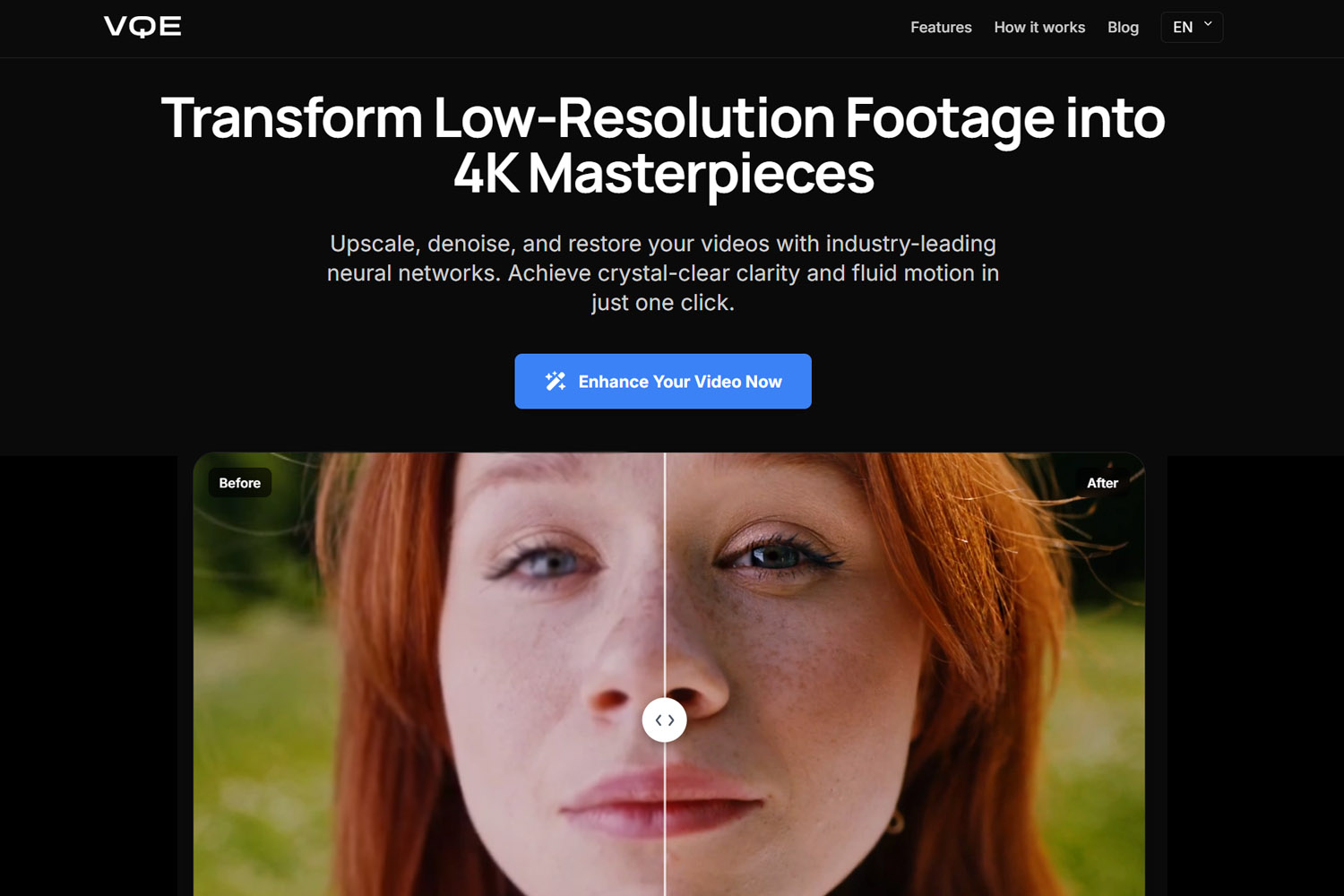
Jenseits des CSI "Enhance"-Memes
Das "Enhance!"-Meme aus Krimiserien repräsentiert eine unmögliche Fantasie von 2005, die 2026 endlich teilweise erreichbar ist. 2005 konnte mathematische Interpolation nur vorhandene Pixel strecken. Sie konnte keine neuen Details erstellen. Die Technologie existierte einfach nicht, um fehlende Informationen auf überzeugende Weise zu rekonstruieren.
Moderne KI ändert diese Gleichung vollständig. KI stellt keine verlorenen Pixel wieder her. Stattdessen ersetzt sie sie durch bessere basierend auf gelernten visuellen Mustern. Wenn Sie ein niedrigauflösendes Video an einen KI-Verbesserer füttern, erkennt das neuronale Netz Muster (Gesichter, Texturen, Objekte) und generiert plausible Details, die zu hochwertigen Trainingsdaten passen. Das ist keine Wiederherstellung. Es ist intelligente Rekonstruktion.
Das Original-Daten-Paradoxon
Das fundamentale Paradoxon der Videoverbesserung: Verbesserung bedeutet plausible Rekonstruktion, nicht Wiederherstellung. Wenn ein Video bei 480p aufgenommen wurde, gibt es keine 4K-Version, die in den Daten versteckt ist. Die Kamera hat diese Details nie aufgenommen. Traditionelle Upscaling-Methoden erkennen diese Einschränkung an, indem sie einfach Pixel strecken, größere Bilder ohne neue Informationen erstellen.
KI-Super-Resolution funktioniert anders. Anstatt Pixel zu strecken, analysiert KI den Inhalt und generiert neue Details, die natürlich und überzeugend aussehen. Die KI erkennt "das ist ein Gesicht" und erstellt Wimpern, Hauttextur und Gesichtszüge basierend darauf, wie Gesichter in hochauflösenden Trainingsdaten erscheinen. Das Ergebnis sieht dramatisch besser aus, aber es sind rekonstruierte Details, nicht wiederhergestellte Informationen.

Diese Unterscheidung ist wichtig, um zu verstehen, was KI-Verbesserung kann und was nicht. KI ist hervorragend, wenn das Quellmaterial genug Informationen für genaue Mustererkennung enthält, ermöglicht es dem neuronalen Netz, fundierte Vorhersagen zu treffen. Wenn das Quellmaterial zu degradiert ist, hat die KI unzureichende Informationen, um damit zu arbeiten, was zu Artefakten und unzuverlässigen Ergebnissen führt. Diese Schwelle zu verstehen hilft Ihnen zu entscheiden, wann Verbesserung einen Versuch wert ist, ob Sie mit unscharfem Material arbeiten, das Entschärfung benötigt oder niedrigauflösendem Video, das Upscaling benötigt.
Traditionelles Upscaling vs. KI-Super-Resolution
Den Unterschied zwischen traditionellem Upscaling und KI-Super-Resolution zu verstehen erklärt, warum moderne Tools dramatisch bessere Ergebnisse produzieren und wann jeder Ansatz Sinn macht.
Traditionelle Methoden: Bikubische und Lanczos-Interpolation
Traditionelle Upscaling-Methoden wie bikubische und Lanczos-Interpolation funktionieren wie das Strecken eines Gummibands, bis es dünner wird. Diese Algorithmen verwenden mathematische Formeln, um zu raten, welche Pixel zwischen bekannten Punkten existieren sollten, erstellen ein größeres Bild, indem sie vorhandene Informationen über mehr Pixel verteilen. Der Bikubische Interpolationsalgorithmus verwendet kubische Polynome, um Pixelwerte zu schätzen, während Lanczos-Resampling eine gefensterte Sinc-Funktion für glattere Ergebnisse anwendet.
Der Prozess ist unkompliziert: Wenn Sie ein 1080p-Bild haben und 4K möchten, erstellt der Algorithmus vier Pixel aus jedem ursprünglichen Pixel durch mathematische Interpolation. Mehr Pixel, aber keine neuen Informationen. Das Ergebnis ist größer, aber nicht unbedingt schärfer, weil Sie dieselbe begrenzte Information über eine größere Leinwand verteilen.
Dieser Ansatz funktioniert akzeptabel für kleine Upscaling-Faktoren (1,5x oder 2x), wird aber bei größeren Skalen problematisch. Bei 4x-Upscaling produzieren traditionelle Methoden unscharfe, weiche Ergebnisse, weil einfach nicht genug Quellinformationen vorhanden sind, um überzeugende Details allein durch mathematische Interpolation zu erstellen.
KI-Super-Resolution: Neumalen von einer unscharfen Skizze
KI-Super-Resolution funktioniert wie das Neumalen eines detaillierten Bildes von einer unscharfen Skizze. Anstatt Pixel zu strecken, analysiert KI Muster und Texturen, um neue Details zu generieren, die zum Inhaltstyp passen. Das neuronale Netz erkennt, was es betrachtet (Gesichter, Gebäude, Natur) und erstellt plausible Details basierend auf Trainingsdaten.

Der wichtige Unterschied: KI-Super-Resolution basiert auf gelernten visuellen Mustern, nicht auf mathematischer Interpolation. Bei der Verarbeitung eines niedrigauflösenden Gesichts streckt die KI nicht nur Pixel. Stattdessen erkennt sie Gesichtsstruktur und generiert Wimpern, Hautporen und feine Details basierend darauf, wie Gesichter in hochauflösenden Trainingsdaten erscheinen.
Dieser Ansatz produziert Ergebnisse, die dramatisch natürlicher aussehen als traditionelles Upscaling. Die KI generiert Details, die zum Inhaltstyp passen, erstellt Texturen, Kanten und feine Strukturen, die für menschliche Betrachter überzeugend aussehen. Die Details sind nicht "real" im Sinne von Wiederherstellung aus dem ursprünglichen Material, aber sie sind plausibel und visuell überlegen.
Super-Resolution: Der technische Begriff
Super-Resolution ist der technische Begriff für KI-basierte Auflösungsverbesserung. Es bezieht sich auf den Prozess der Erhöhung der räumlichen Auflösung über das hinaus, was der ursprüngliche Sensor erfasst hat, verwendet KI, um plausible Details zu generieren, anstatt einfach Pixel zu strecken. Dies unterscheidet moderne KI-Verbesserung von traditionellen Upscaling-Methoden.
Wie moderne KI-Videoverbesserungstools tatsächlich funktionieren
KI-Videoverbesserung im Jahr 2026 ist kein einzelner Algorithmus. Tools wie Topaz Video AI und Video Quality Enhancer kombinieren mehrere spezialisierte Systeme, die zusammenarbeiten, um verschiedene Aspekte der Videoqualität zu verbessern. Diese Komponenten zu verstehen hilft zu erklären, warum moderne Tools bessere Ergebnisse produzieren als frühere Versionen.
Räumliche Verbesserung: Auflösungs-Upscaling
Räumliche Verbesserung erhöht die Auflösung durch Upscaling von niedrigeren Auflösungen (720p, 1080p) zu höheren (1080p, 4K). KI rekonstruiert fehlende Details anstatt Pixel zu strecken, analysiert Muster und Texturen, um plausible hochauflösende Informationen zu generieren.
Der Prozess funktioniert durch Erkennen von Inhaltstypen und Generieren angemessener Details. Ein Gesicht erhält Gesichtszüge, Hauttextur und feine Details. Ein Gebäude erhält architektonische Details, Texturen und strukturelle Elemente. Die KI verwendet Trainingsdaten, um vorherzusagen, wie höherauflösende Versionen aussehen würden, erstellt Ergebnisse, die natürlich und überzeugend erscheinen.
Dies funktioniert besonders gut für 2x bis 4x Upscaling-Faktoren, wo die KI genug Quellinformationen hat, um genaue Vorhersagen zu treffen. Jenseits von 4x werden Ergebnisse weniger zuverlässig, weil die KI unzureichende Informationen hat, um damit zu arbeiten, was zu Artefakten und unrealistischen Details führt.
Temporale Verbesserung: Bewegung und Frame-Interpolation
Temporale Verbesserung verbessert Bewegungsglätte durch Generieren von Zwischenframes, konvertiert 24fps-Material zu 60fps oder erstellt Zeitlupeneffekte. KI generiert Zwischenframes, während natürliche Bewegung erhalten bleibt, analysiert Bewegungsmuster, um realistische Zwischenframes zu erstellen.
Dies funktioniert durch Verstehen, wie sich Objekte durch den Raum bewegen. Die KI analysiert Bewegungsvektoren zwischen Frames und prognostiziert, wie Zwischenframes aussehen sollten, erstellt glatte Bewegung, die natürlich aussieht, anstatt künstlich interpoliert. Das Ergebnis ist flüssige Wiedergabe, die Ruckeln in niedrigen Bildraten-Material eliminiert.
Frame-Interpolation ist besonders effektiv für einfache, vorhersagbare Bewegung wie Gehen, Fahren oder Kamerafahrt. Komplexe Szenen mit vielen überlappenden Objekten oder schneller Bewegungsunschärfe können Artefakte erzeugen, aber gut implementierte temporale Verbesserung produziert überzeugende Ergebnisse.
Intelligente Rauschreduzierung: Körnung von Rauschen trennen
Intelligente Rauschreduzierung unterscheidet zwischen Filmkörnung (gute Textur) und digitalem Rauschen (schlechte Artefakte), bewahrt natürliche Textur, während unerwünschtes Rauschen entfernt wird. KI analysiert Muster über mehrere Frames hinweg, um zu identifizieren, was Rauschen versus echte Details ist, ermöglicht selektive Entfernung, die visuelle Qualität aufrechterhält.

Dies funktioniert, weil Rauschen spezifische Eigenschaften hat: Es ist zufällig, ändert sich zwischen Frames und erscheint als Körnung oder Farbflecken. Echte Details sind konsistent und folgen Mustern, ermöglicht es der KI, zwischen den beiden zu unterscheiden. Durch Analyse mehrerer Frames zusammen kann die KI Rauschen entfernen, während Texturen, Kanten und wichtige Details erhalten bleiben.
Das Ergebnis ist saubereres Material, das natürliches Aussehen aufrechterhält, vermeidet das plastische, überglättete Aussehen, das traditionelle Rauschreduzierungsmethoden produzieren. Moderne KI-Rauschreduzierung bewahrt Filmkörnung, wenn angemessen, während Sensorrauschen und Komprimierungsartefakte entfernt werden.
Gesichtsrekonstruktion und -verfeinerung
Gesichtsrekonstruktion verwendet spezialisierte neuronale Modelle, die auf Gesichtsstruktur trainiert wurden, um Gesichter zu verbessern, während natürliches Aussehen aufrechterhalten wird. Diese Modelle stabilisieren Augen, Hauttextur und Ausdrücke, verhindern das "wächserne Haut"-Problem, das Allzweck-Upscaler plagt.

Professionelle Tools verwenden gesichtsspezifische Modelle, weil menschliche Gehirne sich intensiv auf Gesichter konzentrieren. Wenn Gesichter falsch aussehen, fühlt sich das gesamte Video falsch an, auch wenn Hintergründe perfekt verbessert sind. Gesichtsrekonstruktionsmodelle erkennen Gesichtsanatomie und generieren Details, die natürlichen menschlichen Gesichtszügen entsprechen, halten realistische Erscheinung während der gesamten Verbesserung aufrecht.
Dies ist entscheidend für Material mit Menschen, besonders Interviews, Porträts oder jeden Inhalt, wo Gesichter prominent sind. Ohne spezialisierte Gesichtsrekonstruktion könnten Hintergründe 4K aussehen, während Gesichter unscharf bleiben, was eine störende Diskrepanz schafft, die das gesamte Video schlechter aussehen lässt als das Original.
Bild-KI vs. Video-KI: Warum Video viel schwieriger ist
Videoverbesserung ist grundlegend komplexer als Bildverbesserung, weil Video zeitliche Konsistenz erfordert. Details müssen über Frames hinweg stabil bleiben, nicht nur in einem einzelnen Standbild gut aussehen.
Warum Frame-für-Frame-Verbesserung versagt
Jeden Frame unabhängig zu verarbeiten verursacht mehrere Probleme, die Video schlechter aussehen lassen als das Original. Jeder unabhängig verbesserte Frame erzeugt flackernde Texturen, kriechende Details und instabile Gesichter, die sofort während der Wiedergabe bemerkbar sind.
Das Problem ist, dass unabhängige Frame-Verarbeitung keinen Kontext berücksichtigt. Eine Textur könnte in einem Frame scharf aussehen, aber im nächsten anders, erzeugt einen schimmernden Effekt, der ablenkend und unnatürlich ist. Gesichter könnten zwischen Frames das Aussehen ändern, mit Augen oder Hauttextur, die sich auf Weisen verschieben, die falsch aussehen.
Diese Artefakte sind auffälliger als die ursprüngliche niedrige Qualität, macht Frame-für-Frame-Verbesserung kontraproduktiv. Das Video könnte höhere Auflösung haben, aber die zeitlichen Inkonsistenzen lassen es insgesamt schlechter aussehen.
Der echte Durchbruch: Zeitliche Konsistenz
Moderne Videoverbesserungstools lösen dies, indem sie mehrere Frames zusammen analysieren, stellen sicher, dass Details über die Zeit stabil bleiben. Zeitliche Konsistenzalgorithmen analysieren den aktuellen Frame zusammen mit mehreren Frames davor und danach, verwenden Informationen aus umgebenden Frames, um Stabilität aufrechtzuerhalten.
Details müssen über die Zeit stabil bleiben, nicht nur in einem Standbild gut aussehen. Deshalb konzentrieren sich seriöse Tools wie Topaz Video AI und Cloud-Plattformen wie Video Quality Enhancer stark auf temporale Analyse. Der Verbesserungsprozess berücksichtigt die gesamte Sequenz, nicht nur einzelne Frames.
Dieses temporale Bewusstsein verhindert Flackern, Kriech- und Instabilitätsprobleme. Texturen bleiben konsistent, Gesichter bleiben stabil, und Bewegung sieht natürlich aus, weil die KI Informationen aus mehreren Frames verwendet, um Kohärenz aufrechtzuerhalten. Das Ergebnis ist Verbesserung, die sowohl in Standbildern als auch während der Wiedergabe gut aussieht.
Diffusionsmodelle erklärt
Diffusionsmodelle repräsentieren einen bedeutenden Fortschritt in der KI-Videoverbesserung, bieten überlegene Detailgenerierung im Vergleich zu älteren GAN-basierten Systemen.
Was Diffusionsmodelle wirklich sind
Diffusionsmodelle sind generative Modelle, die trainiert wurden, plausible visuelle Details vorherzusagen durch einen Prozess iterativer Verfeinerung. Sie funktionieren, indem sie lernen, einen Rausch-Hinzufügungsprozess umzukehren, bauen schrittweise Details aus niedrigauflösenden oder verrauschten Eingaben auf.
Diese Modelle sind extrem stark darin, Texturen, Gesichter und feine Strukturen zu generieren, weil sie auf riesigen Datensätzen hochwertiger Bilder und Videos trainiert wurden. Der Trainingsprozess lehrt sie, Muster zu erkennen und Details zu generieren, die natürliches Aussehen entsprechen, produziert Ergebnisse, die für menschliche Betrachter überzeugend aussehen.
Stable Diffusion: Bildmodell, nicht natives Video
Stable Diffusion ist ein Bildmodell, kein natives Videomodell, was Herausforderungen schafft, wenn es auf Videoverbesserung angewendet wird. Wenn für Video verwendet, werden Diffusionsmodelle typischerweise Frame-für-Frame angewendet, dann mit temporaler Führung kombiniert, um Flackern zu reduzieren.
Dieser hybride Ansatz funktioniert, ist aber nicht ideal. Frame-für-Frame-Diffusion kann zeitliche Inkonsistenzen erzeugen, erfordert zusätzliche Verarbeitung, um Stabilität über Frames hinweg aufrechtzuerhalten. Die temporale Führung hilft, aber es ist ein Workaround für ein Modell, das nicht für Video entwickelt wurde.
Die 2026 Spitze: Hybride Pipelines
Fortgeschrittene Tools im Jahr 2026 verwenden hybride Pipelines, die klassische Video-Super-Resolution mit diffusionsbasierter Detailverfeinerung kombinieren. Dieser Ansatz geht über ältere GAN-only-Systeme hinaus, nutzt die Stärken sowohl klassischer als auch generativer Methoden.
Der hybride Ansatz funktioniert, indem klassische Super-Resolution für Basisverbesserung verwendet wird, dann Diffusionsmodelle für Detailverfeinerung angewendet werden. Dies produziert Ergebnisse, die sowohl stabil (von klassischen Methoden) als auch detailliert (von Diffusionsmodellen) sind, schafft Verbesserung, die natürlich und überzeugend aussieht.
Wenn KI zu weit geht: Das "Fake"-Aussehen-Problem
KI-Verbesserung kann Artefakte produzieren, die Video künstlich aussehen lassen, besonders wenn die Verarbeitung zu aggressiv ist oder das Quellmaterial zu degradiert ist.
Häufige Fehlermodi
Artefaktbildung tritt auf, wenn KI Muster falsch interpretiert, erstellt Details, die nicht zum Inhalt passen. Steine könnten erscheinen, wo keine sind, Stofftexturen könnten falsch generiert werden, oder Muster könnten erstellt werden, die unnatürlich aussehen.
Wächserne Haut tritt auf, wenn KI natürliche Poren und Textur entfernt, erzeugt ein plastisches Aussehen, das sofort bemerkbar ist. Dies tritt auf, wenn Verbesserungsalgorithmen zu aggressiv glätten, entfernen die feinen Variationen, die Haut real aussehen lassen.
Über-Schärfung erzeugt Details, die aufgemalt aussehen, mit Kanten, die zu scharf sind, und Texturen, die künstlich erscheinen. Die Details könnten technisch "korrekt" sein, passen aber nicht zum natürlichen Aussehen, erzeugen einen Uncanny-Valley-Effekt.
Die moderne Lösung: Kontrollierte Verbesserung
Professionelle Tools adressieren diese Probleme durch kontrollierte Verbesserungsstärke und Filmkörnungsbewahrung. Kontrollierte Verbesserung ermöglicht Benutzern, Verarbeitungsintensität anzupassen, findet das Gleichgewicht zwischen Verbesserung und natürlichem Aussehen.
Filmkörnungsbewahrung oder -reinjektion hält natürliche Textur aufrecht, die während der Verarbeitung verloren gehen könnte. Einige Tools können ursprüngliche Körnung analysieren und bewahren oder synthetische Körnung nach Verbesserung hinzufügen, halten das natürliche Aussehen aufrecht, das Zuschauer erwarten.
Professionelle Tools exponieren Abstimmungssteuerungen, um Über-Verarbeitung zu vermeiden, geben Benutzern Kontrolle über Verbesserungsparameter. Dies ermöglicht Feinabstimmung, die natürliche Ergebnisse produziert, anstatt künstlich aussehende Verbesserung.
Reale Benchmarks: Was verschiedene Tools erreichen können
Zu verstehen, was verschiedene Tools tatsächlich erreichen können, hilft, realistische Erwartungen zu setzen und den richtigen Ansatz für Ihr Material zu wählen.
Niedrigqualitätsquellen: VHS, MiniDV, 480p
Niedrigqualitätsquellen zeigen große wahrgenommene Verbesserung, wenn mit modernen KI-Tools verbessert. VHS-Bänder, MiniDV-Material und 480p-Videos können auf 1080p oder 4K vergrößert werden mit Ergebnissen, die dramatisch besser aussehen als das Original.
Die Ergebnisse sind immer noch stilisiert, nicht magisch modern. Verbessertes Material behält den Charakter des Originals, während es deutlich schärfer und sauberer aussieht. Die KI kann die Einschränkungen des Quellmaterials nicht vollständig eliminieren, aber sie kann Ergebnisse schaffen, die visuell überlegen und ansehbarer sind.
Dies funktioniert am besten, wenn Quellmaterial minimale Komprimierungsartefakte und vernünftigen Fokus hat. Stark degradiertes Material mit schwerer Kompression oder Bewegungsunschärfe wird weniger beeindruckende Ergebnisse produzieren, aber selbst in diesen Fällen können moderne Tools merkliche Verbesserung schaffen. Bei der Arbeit mit unscharfem Material hilft das Verstehen der Art der Unschärfe zu bestimmen, ob Verbesserung effektiv sein wird.
Mittlere Qualitätsquellen: 1080p Smartphones, DSLRs
Mittlere Qualitätsquellen erreichen nahezu native 4K wahrgenommene Qualität, wenn mit professionellen Tools verbessert. Modernes Smartphone-Material und DSLR-Video, das bei 1080p aufgenommen wurde, kann auf 4K vergrößert werden mit Ergebnissen, die fast so gut aussehen wie natives 4K-Material.
Hier glänzen Tools wie Topaz Video AI und Video Quality Enhancer am meisten. Das Quellmaterial enthält genug Informationen für genaue KI-Vorhersagen, ermöglicht es den Tools, Details zu generieren, die natürlich und überzeugend aussehen. Das verbesserte Material behält den Charakter des Originals, während es höhere Auflösung und wahrgenommene Qualität erreicht.
Der Schlüssel ist, mit anständigem Quellmaterial zu beginnen. Ein 1080p-Video, das bei hoher Bitrate aufgenommen wurde, wird besser vergrößert als ein 1080p-Video, das bei niedriger Bitrate aufgenommen wurde, weil die höhere Bitrate mehr Informationen für die KI bewahrt, mit denen sie arbeiten kann.
Metriken vs. menschliches Sehen: Warum "Sieht besser aus" wichtig ist
KI-verbessertes Video könnte bei technischen Metriken wie VMAF niedrigere Werte erzielen, während es für menschliche Betrachter dramatisch besser aussieht. Dieses Paradoxon offenbart, warum wahrgenommene Qualität wichtiger ist als Pixel-Level-Genauigkeit.
Das Genauigkeitsparadoxon
KI-verbessertes Video könnte bei Metriken wie VMAF niedrigere Werte erzielen, weil der Verbesserungsprozess Details erstellt, die nicht im Original waren. Technische Metriken messen Genauigkeit zur Quelle, aber KI-Verbesserung erstellt absichtlich neue Details, was Genauigkeitswerte senken kann. Die VMAF (Video Multi-method Assessment Fusion) Metrik, entwickelt von Netflix, kombiniert mehrere Qualitätsmessungen, um menschliche Wahrnehmung vorherzusagen, aber sie misst Treue zur Quelle anstatt wahrgenommener Verbesserung.
Dennoch sieht das verbesserte Video für menschliche Betrachter dramatisch besser aus, die sich mehr um Klarheit, Gesichter und Bewegungsstabilität kümmern als um Pixel-Level-Genauigkeit. Dies schafft eine Situation, wo technische Metriken niedrigere Qualität vorschlagen, aber menschliche Wahrnehmung höhere Qualität anzeigt.
Warum dies passiert
KI priorisiert wahrgenommene Qualität, nicht Pixel-Level-Genauigkeit. Der Verbesserungsprozess ist darauf ausgelegt, Ergebnisse zu schaffen, die für Menschen gut aussehen, nicht um das Original Pixel-für-Pixel zu entsprechen. Dies bedeutet, dass KI Details generieren könnte, die wahrgenommene Qualität verbessern, auch wenn es technische Genauigkeit reduziert.
Menschen kümmern sich mehr um Klarheit, Gesichter und Bewegungsstabilität als darum, ob jedes Pixel dem Original entspricht. Wenn ein Gesicht schärfer und natürlicher aussieht, nehmen Zuschauer höhere Qualität wahr, auch wenn die verbesserte Version nicht Pixel-für-Pixel dem Original entspricht. Wenn Sie unsicher sind, ob Ihr Material für Verbesserung geeignet ist, kann ChatGPT helfen, Ihre Videoqualität zu analysieren und den richtigen Ansatz empfehlen.
Diese Unterscheidung ist wichtig für das Verstehen von Verbesserungsergebnissen. Technische Metriken bieten eine Perspektive, aber menschliche Wahrnehmung bietet eine andere, und für Videoverbesserung ist menschliche Wahrnehmung das, was letztendlich zählt.
Wie man erkennt, ob ein Videoverbesserungstool tatsächlich gut ist
Die meisten Reviews konzentrieren sich auf Ausgabequalität, ignorieren aber kritische Faktoren, die bestimmen, ob Verbesserung Video tatsächlich verbessert oder neue Probleme einführt.
Die Tests, die die meisten Reviews ignorieren
Temporales Flackertesten überprüft, ob Textur zwischen Frames schimmert. Ein gutes Verbesserungstool hält stabile Texturen während des gesamten Videos aufrecht, während schlechte Tools Flackern erzeugen, das sofort während der Wiedergabe bemerkbar ist.
Gesichtsstabilitätstesten verifiziert, ob Augen und Haut konsistent bleiben über Frames hinweg. Gesichter sollten während des gesamten Videos stabil und natürlich aussehen, nicht das Aussehen zwischen Frames auf Weisen ändern, die falsch aussehen.
Bewegungsintegritätstesten stellt sicher, dass keine Verzerrung während schneller Bewegung auftritt. Verbessertes Video sollte natürliche Bewegung aufrechterhalten, mit Objekten, die sich glatt bewegen, ohne Verzerrung oder Artefakte während schneller Action.
Pro-Level-Einsichten
Referenz-Frame-Analyse offenbart, wie KI Details von nahen scharfen Frames entlehnt. Fortgeschrittene Tools analysieren mehrere Frames, um die schärfste Version jedes Elements zu finden, verwenden dann diese Informationen, um andere Frames zu verbessern. Dies schafft genauere Verbesserung als unabhängige Verarbeitung jedes Frames.
Über-Verarbeitung vermeiden bedeutet, subtile Verbesserung schlägt aggressive Rekonstruktion. Die besten Ergebnisse kommen von moderater Verbesserung, die Qualität verbessert, ohne Artefakte einzuführen. Aggressive Verarbeitung könnte mehr Details schaffen, aber sie sieht oft künstlich aus und reduziert Gesamtqualität.
Hardware-Realitätsprüfung: lokale Tools erfordern leistungsstarke GPUs, während Cloud-Plattformen diese Barriere vollständig entfernen. Desktop-Software wie Topaz Video AI benötigt NVIDIA RTX-Serie oder Apple Silicon GPUs für praktische Verarbeitungsgeschwindigkeiten. Cloud-Lösungen wie Video Quality Enhancer eliminieren Hardwareanforderungen, machen professionelle Verbesserung zugänglich, unabhängig vom lokalen Setup. Wenn Sie mit ChatGPT arbeiten, um Ihren Verbesserungs-Workflow zu leiten, kann es Ihnen helfen, zwischen lokalen und Cloud-Ansätzen basierend auf Ihrer Hardware zu wählen.
Endgültiges Urteil: Kann KI die Videoqualität wirklich verbessern?
Die Antwort ist ja, aber mit wichtigen Einschränkungen, die erklären, wann Verbesserung funktioniert und wann nicht.
KI stellt keine verlorene Realität wieder her
KI stellt keine verlorene Realität wieder her. Stattdessen rekonstruiert sie glaubwürdige Details. Wenn ein Video bei 480p aufgenommen wurde, gibt es keine 4K-Version, die in den Daten versteckt ist. Die Kamera hat diese Details nie aufgenommen. KI-Verbesserung erstellt plausible Details basierend auf Trainingsdaten, nicht wiederhergestellte Informationen.
Diese Unterscheidung ist wichtig für das Verstehen, was Verbesserung erreichen kann. Das verbesserte Video repräsentiert, was die KI denkt, dass dort sein sollte, nicht unbedingt das, was tatsächlich aufgenommen wurde. Dies ist Rekonstruktion, nicht Wiederherstellung.
Wenn richtig durchgeführt, sind Ergebnisse stabil, natürlich und visuell überlegen
Wenn richtig durchgeführt, produziert KI-Verbesserung Ergebnisse, die stabil, natürlich und visuell überlegen sind. Moderne Tools mit zeitlicher Konsistenz schaffen Verbesserung, die sowohl in Standbildern als auch während der Wiedergabe gut aussieht, hält natürliches Aussehen während des gesamten Videos aufrecht.
Der Schlüssel ist, das richtige Tool für Ihr Quellmaterial zu verwenden und angemessene Verbesserungsstärke anzuwenden. Professionelle Tools mit ordnungsgemäßer temporaler Analyse produzieren Ergebnisse, die überzeugend und natürlich aussehen, vermeiden die Artefakte und Instabilität, die Frame-für-Frame-Verarbeitung plagen.
KI-Videoverbesserung geht nicht um Wahrheit: Es geht um überzeugende Klarheit
KI-Videoverbesserung geht nicht um Wahrheit. Es geht um überzeugende Klarheit. Das Ziel ist nicht, verlorene Informationen wiederherzustellen, sondern Ergebnisse zu schaffen, die für menschliche Betrachter besser aussehen. Wenn das verbesserte Video schärfer, sauberer und natürlicher aussieht, hat es seinen Zweck erfüllt, auch wenn die Details technisch "halluziniert" sind.
Diese Perspektive hilft, realistische Erwartungen zu setzen. KI-Verbesserung schafft glaubwürdige, visuell überlegene Ergebnisse, nicht perfekte Rekonstruktionen verlorener Informationen. Die Technologie funktioniert am besten, wenn Quellmaterial genug Informationen für genaue Mustererkennung enthält, ermöglicht es der KI, Details zu generieren, die natürlich und überzeugend aussehen.