هل يمكن للذكاء الاصطناعي حقًا تحسين جودة الفيديو؟

سؤال "هل يمكن للذكاء الاصطناعي حقًا تحسين جودة الفيديو؟" له إجابة معقدة تتجاوز نعم أو لا البسيطة. الذكاء الاصطناعي الحديث لا يستعيد البكسل المفقودة. بدلاً من ذلك، يستبدلها بأخرى أفضل من خلال إعادة البناء الذكية. هذا التمييز مهم لأنه يفسر سبب عمل تحسين الذكاء الاصطناعي بشكل جميل في بعض السيناريوهات بينما يفشل في أخرى، ولماذا تبدو النتائج مقنعة رغم أنها تقنيًا تفاصيل "مهلوسة".
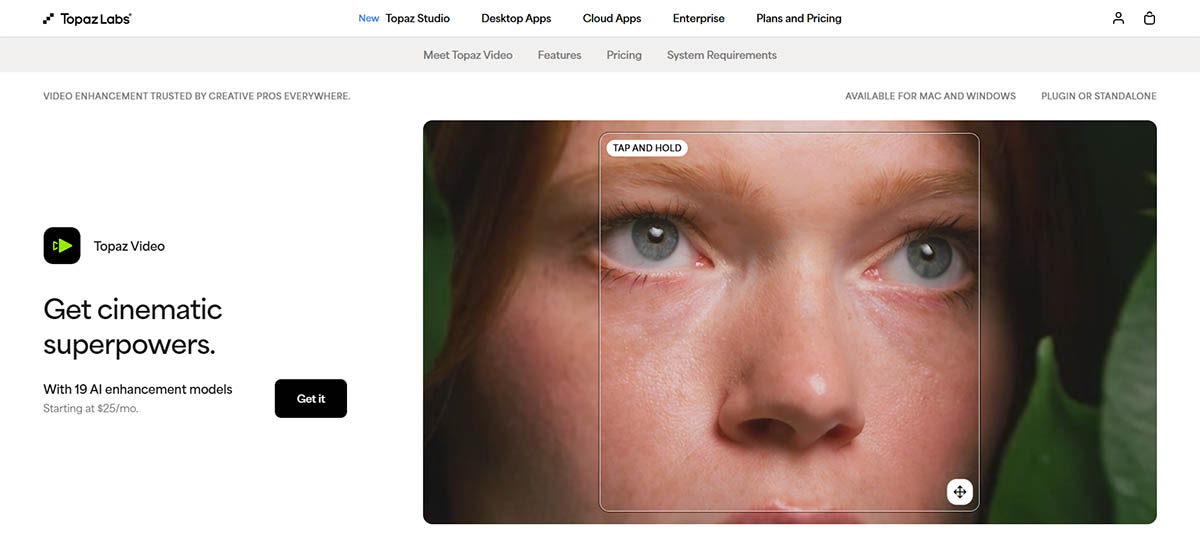
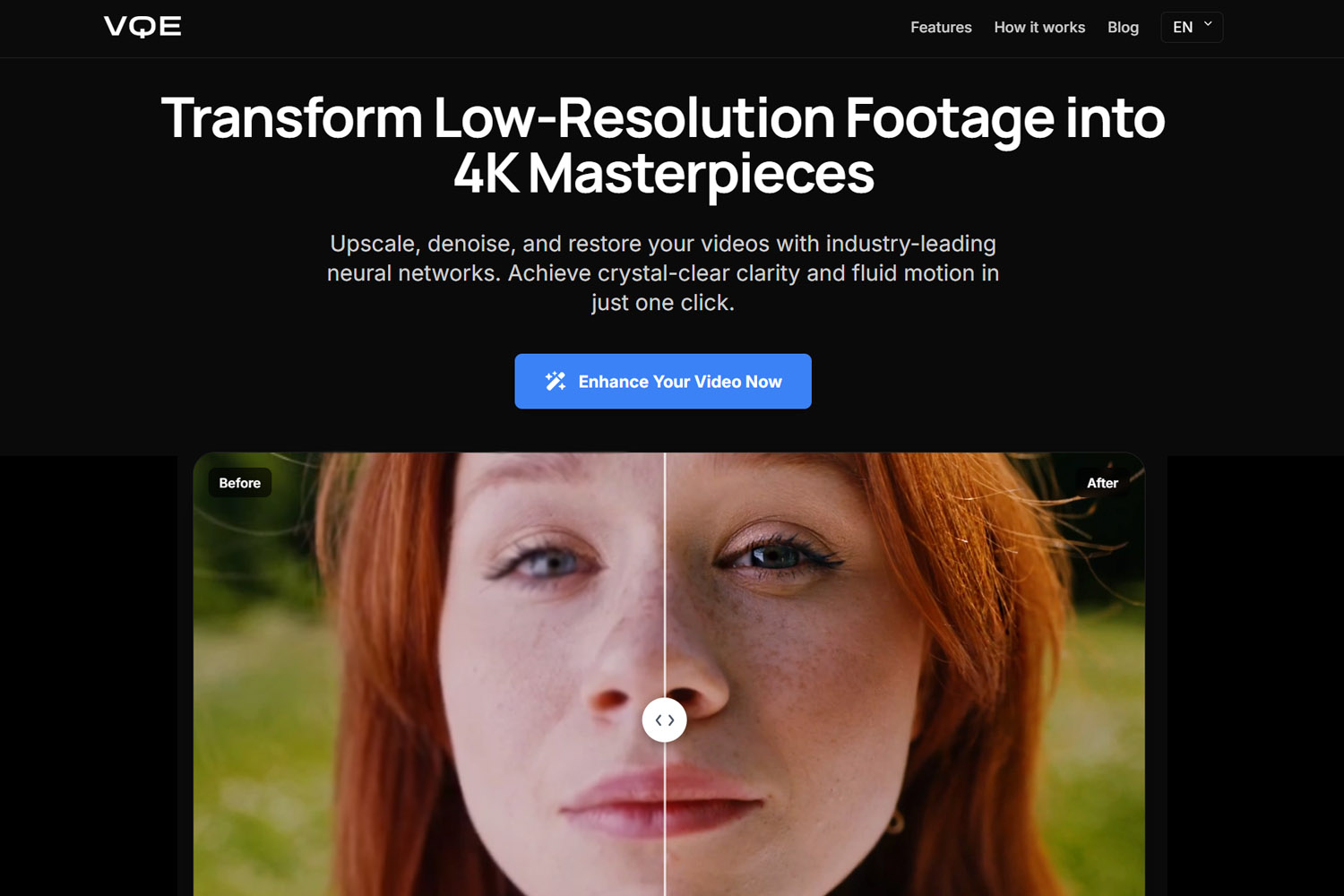
تستكشف هذه المقالة العلم وراء تحسين الفيديو بالذكاء الاصطناعي، من الفرق الأساسي بين الرفع التقليدي والدقة الفائقة بالذكاء الاصطناعي إلى الاختراق في الاتساق الزمني الذي يجعل الأدوات الحديثة قابلة للتطبيق. سنفحص كيف تعالج أدوات مثل Topaz Video AI والمنصات السحابية الفيديو، ولماذا تحسين الفيديو أصعب من تحسين الصور، وما تكشفه المعايير عن النتائج في العالم الحقيقي.
ما وراء ميم "تحسين" من CSI
ميم "تحسين!" من برامج الجريمة يمثل خيالًا مستحيلًا من عام 2005 أصبح قابلاً للتحقيق جزئيًا أخيرًا في 2026. في عام 2005، كان الاستيفاء الرياضي يمكنه فقط تمديد البكسل الموجودة. لم يستطع إنشاء تفاصيل جديدة. التكنولوجيا ببساطة لم تكن موجودة لإعادة بناء المعلومات المفقودة بطريقة مقنعة.
الذكاء الاصطناعي الحديث يغير هذه المعادلة تمامًا. الذكاء الاصطناعي لا يستعيد البكسل المفقودة. بدلاً من ذلك، يستبدلها بأخرى أفضل بناءً على الأنماط البصرية المتعلمة. عندما تغذي فيديو منخفض الدقة إلى محسّن ذكاء اصطناعي، تتعرف الشبكة العصبية على الأنماط (الوجوه، الملمس، الكائنات) وتولد تفاصيل معقولة تطابق بيانات التدريب عالية الجودة. هذا ليس استعادة. إنه إعادة بناء ذكية.
مفارقة البيانات الأصلية
المفارقة الأساسية لتحسين الفيديو: التحسين يعني إعادة بناء معقولة، وليس استعادة. إذا تم تسجيل فيديو بدقة 480p، فلا توجد نسخة 4K مخفية في البيانات. الكاميرا لم تلتقط تلك التفاصيل أبدًا. طرق الرفع التقليدية تعترف بهذا القيد ببساطة عن طريق تمديد البكسل، مما يخلق صورًا أكبر دون معلومات جديدة.
الدقة الفائقة بالذكاء الاصطناعي تعمل بشكل مختلف. بدلاً من تمديد البكسل، يحلل الذكاء الاصطناعي المحتوى ويولد تفاصيل جديدة تبدو طبيعية ومقنعة. يتعرف الذكاء الاصطناعي على "هذا وجه" وينشئ رموشًا، وملمس جلد، وميزات وجهية بناءً على كيفية ظهور الوجوه في بيانات التدريب عالية الدقة. النتيجة تبدو أفضل بشكل كبير، لكنها تفاصيل معاد بناؤها، وليست معلومات مستعادة.

هذا التمييز مهم لفهم ما يمكن لتحسين الذكاء الاصطناعي وما لا يمكنه فعله. يتفوق الذكاء الاصطناعي عندما تحتوي المادة المصدر على معلومات كافية للتعرف الدقيق على الأنماط، مما يسمح للشبكة العصبية بإجراء تنبؤات مستنيرة. عندما تكون المادة المصدر متدهورة جدًا، لا يمتلك الذكاء الاصطناعي معلومات كافية للعمل معها، مما يؤدي إلى أ artifacts ونتائج غير موثوقة. فهم هذا العتبة يساعدك على تحديد متى يستحق التحسين المحاولة، سواء كنت تعمل مع لقطات ضبابية تحتاج إلى إزالة الضبابية أو فيديو منخفض الدقة يحتاج إلى رفع.
الرفع التقليدي مقابل الدقة الفائقة بالذكاء الاصطناعي
فهم الفرق بين الرفع التقليدي والدقة الفائقة بالذكاء الاصطناعي يفسر سبب إنتاج الأدوات الحديثة لنتائج أفضل بشكل كبير ومتى يكون كل نهج منطقيًا.
الطرق التقليدية: الاستيفاء Bicubic وLanczos
طرق الرفع التقليدية مثل الاستيفاء bicubic وLanczos تعمل مثل تمديد شريط مطاطي حتى يصبح أرق. تستخدم هذه الخوارزميات صيغًا رياضية لتخمين ما يجب أن توجد البكسل بين النقاط المعروفة، مما يخلق صورة أكبر عن طريق توزيع المعلومات الموجودة عبر المزيد من البكسل. خوارزمية الاستيفاء bicubic تستخدم متعددات حدود مكعبة لتقدير قيم البكسل، بينما إعادة أخذ العينات Lanczos تطبق دالة sinc محددة النافذة لنتائج أكثر سلاسة.
العملية مباشرة: إذا كان لديك صورة 1080p وتريد 4K، تنشئ الخوارزمية أربعة بكسل من كل بكسل أصلي باستخدام الاستيفاء الرياضي. المزيد من البكسل، لكن لا معلومات جديدة. النتيجة أكبر لكن ليست بالضرورة أكثر حدة، لأنك تنشر نفس المعلومات المحدودة عبر لوحة أكبر.
هذا النهج يعمل بشكل مقبول لعوامل الرفع الصغيرة (1.5x أو 2x)، لكنه يصبح إشكاليًا على نطاقات أكبر. في الرفع 4x، تنتج الطرق التقليدية نتائج ضبابية وناعمة لأنه ببساطة لا توجد معلومات مصدر كافية لإنشاء تفاصيل مقنعة من خلال الاستيفاء الرياضي وحده.
الدقة الفائقة بالذكاء الاصطناعي: إعادة رسم من رسم ضبابي
الدقة الفائقة بالذكاء الاصطناعي تعمل مثل إعادة رسم صورة مفصلة من رسم ضبابي. بدلاً من تمديد البكسل، يحلل الذكاء الاصطناعي الأنماط والملمس لإنشاء تفاصيل جديدة تناسب نوع المحتوى. تتعرف الشبكة العصبية على ما تنظر إليه (الوجوه، المباني، الطبيعة) وتنشئ تفاصيل معقولة بناءً على بيانات التدريب.

الفرق الرئيسي: الدقة الفائقة بالذكاء الاصطناعي تعتمد على الأنماط البصرية المتعلمة، وليس الاستيفاء الرياضي. عند معالجة وجه منخفض الدقة، لا يمدد الذكاء الاصطناعي البكسل فقط. بدلاً من ذلك، يتعرف على بنية الوجه وينشئ رموشًا، ومسام الجلد، وتفاصيل دقيقة بناءً على كيفية ظهور الوجوه في بيانات التدريب عالية الدقة.
هذا النهج ينتج نتائج تبدو أكثر طبيعية بشكل كبير من الرفع التقليدي. يولد الذكاء الاصطناعي تفاصيل تطابق نوع المحتوى، مما يخلق ملمسًا، وحوافًا، وبنى دقيقة تبدو مقنعة للمشاهدين البشر. التفاصيل ليست "حقيقية" بمعنى استعادتها من اللقطات الأصلية، لكنها معقولة ومتفوقة بصريًا.
الدقة الفائقة: المصطلح التقني
الدقة الفائقة هي المصطلح التقني لتحسين الدقة القائم على الذكاء الاصطناعي. تشير إلى عملية زيادة الدقة المكانية بما يتجاوز ما التقطه المستشعر الأصلي، باستخدام الذكاء الاصطناعي لإنشاء تفاصيل معقولة بدلاً من تمديد البكسل ببساطة. هذا يميز تحسين الذكاء الاصطناعي الحديث عن طرق الرفع التقليدية.
كيف تعمل أدوات تحسين الفيديو بالذكاء الاصطناعي الحديثة فعليًا
تحسين الفيديو بالذكاء الاصطناعي في 2026 ليس خوارزمية واحدة. أدوات مثل Topaz Video AI ومحسّن جودة الفيديو تجمع أنظمة متخصصة متعددة تعمل معًا لتحسين جوانب مختلفة من جودة الفيديو. فهم هذه المكونات يساعد في شرح سبب إنتاج الأدوات الحديثة لنتائج أفضل من الإصدارات السابقة.
التحسين المكاني: رفع الدقة
التحسين المكاني يزيد الدقة عن طريق الرفع من الدقات المنخفضة (720p، 1080p) إلى الدقات الأعلى (1080p، 4K). يعيد الذكاء الاصطناعي بناء التفاصيل المفقودة بدلاً من تمديد البكسل، مما يحلل الأنماط والملمس لإنشاء معلومات عالية الدقة معقولة.
العملية تعمل عن طريق التعرف على أنواع المحتوى وإنشاء التفاصيل المناسبة. الوجه يحصل على ميزات وجهية، وملمس جلد، وتفاصيل دقيقة. المبنى يحصل على تفاصيل معمارية، وملمس، وعناصر هيكلية. يستخدم الذكاء الاصطناعي بيانات التدريب للتنبؤ بكيفية ظهور الإصدارات عالية الدقة، مما يخلق نتائج تبدو طبيعية ومقنعة.
هذا يعمل بشكل جيد بشكل خاص لعوامل الرفع من 2x إلى 4x، حيث يمتلك الذكاء الاصطناعي معلومات مصدر كافية لإجراء تنبؤات دقيقة. بعد 4x، تصبح النتائج أقل موثوقية لأن الذكاء الاصطناعي لا يمتلك معلومات كافية للعمل معها، مما يؤدي إلى أ artifacts وتفاصيل غير واقعية.
التحسين الزمني: الحركة واستيفاء الإطارات
التحسين الزمني يحسن سلاسة الحركة عن طريق إنشاء إطارات وسيطة، وتحويل لقطات 24fps إلى 60fps أو إنشاء تأثيرات الحركة البطيئة. يولد الذكاء الاصطناعي إطارات وسيطة مع الحفاظ على الحركة الطبيعية، مما يحلل أنماط الحركة لإنشاء إطارات بينية واقعية.
هذا يعمل عن طريق فهم كيفية تحرك الكائنات عبر الفضاء. يحلل الذكاء الاصطناعي متجهات الحركة بين الإطارات ويتنبأ بكيفية ظهور الإطارات الوسيطة، مما يخلق حركة سلسة تبدو طبيعية بدلاً من الاستيفاء الاصطناعي. النتيجة هي تشغيل سلس يزيل التقطع في اللقطات منخفضة معدل الإطارات.
استيفاء الإطارات فعال بشكل خاص للحركة البسيطة والقابلة للتنبؤ مثل المشي، أو القيادة، أو تحريك الكاميرا. المشاهد المعقدة مع العديد من الكائنات المتداخلة أو ضبابية الحركة السريعة يمكن أن تخلق أ artifacts، لكن التحسين الزمني المنفذ جيدًا ينتج نتائج مقنعة.
تقليل الضوضاء الذكي: فصل الحبيبات عن الضوضاء
تقليل الضوضاء الذكي يميز بين حبيبات الفيلم (ملمس جيد) والضوضاء الرقمية (أ artifacts سيئة)، مما يحافظ على الملمس الطبيعي مع إزالة الضوضاء غير المرغوب فيها. يحلل الذكاء الاصطناعي الأنماط عبر إطارات متعددة لتحديد ما هو الضوضاء مقابل ما هو التفاصيل الحقيقية، مما يسمح بالإزالة الانتقائية التي تحافظ على الجودة البصرية.

هذا يعمل لأن الضوضاء لها خصائص محددة: إنها عشوائية، وتتغير بين الإطارات، وتظهر كحبيبات أو بقع لونية. التفاصيل الحقيقية متسقة وتتبع الأنماط، مما يسمح للذكاء الاصطناعي بالتمييز بين الاثنين. عن طريق تحليل إطارات متعددة معًا، يمكن للذكاء الاصطناعي إزالة الضوضاء مع الحفاظ على الملمس، والحواف، والتفاصيل المهمة.
النتيجة هي لقطات أنظف تحافظ على المظهر الطبيعي، مما يتجنب المظهر البلاستيكي، المفرط النعومة الذي تنتجه طرق تقليل الضوضاء التقليدية. تقليل الضوضاء بالذكاء الاصطناعي الحديث يحافظ على حبيبات الفيلم عند الاقتضاء مع إزالة ضوضاء المستشعر وأ artifacts الضغط.
استعادة الوجه وتحسينه
استعادة الوجه تستخدم نماذج عصبية متخصصة مدربة على بنية الوجه لتحسين الوجوه مع الحفاظ على المظهر الطبيعي. هذه النماذج تثبت العيون، وملمس الجلد، والتعبيرات، مما يمنع مشكلة "الجلد الشمعي" التي تؤثر على محسّنات الأغراض العامة.

الأدوات الاحترافية تستخدم نماذج خاصة بالوجه لأن أدمغة البشر تركز بشدة على الوجوه. إذا بدت الوجوه خاطئة، يشعر الفيديو بالكامل بالخطأ، حتى لو كانت الخلفيات محسّنة بشكل مثالي. نماذج استعادة الوجه تتعرف على تشريح الوجه وتولد تفاصيل تطابق الميزات البشرية الطبيعية، مما يحافظ على المظهر الواقعي طوال التحسين.
هذا حاسم للقطات التي تحتوي على أشخاص، خاصة المقابلات، أو الصور الشخصية، أو أي محتوى حيث الوجوه بارزة. بدون استعادة الوجه المتخصصة، قد تبدو الخلفيات 4K بينما تبقى الوجوه ضبابية، مما يخلق انفصالًا مزعجًا يجعل الفيديو بالكامل يبدو أسوأ من الأصلي.
ذكاء اصطناعي الصور مقابل ذكاء اصطناعي الفيديو: لماذا الفيديو أصعب بكثير
تحسين الفيديو معقد بشكل أساسي أكثر من تحسين الصور لأن الفيديو يتطلب الاتساق الزمني. يجب أن تبقى التفاصيل مستقرة عبر الإطارات، وليس فقط أن تبدو جيدة في صورة ثابتة واحدة.
لماذا يفشل التحسين إطارًا بإطار
معالجة كل إطار بشكل مستقل تسبب عدة مشاكل تجعل الفيديو يبدو أسوأ من الأصلي. كل إطار محسّن بشكل مستقل يخلق ملمسًا متوهجًا، وتفاصيل زاحفة، ووجوه غير مستقرة ملحوظة فورًا أثناء التشغيل.
المشكلة هي أن معالجة الإطارات المستقلة لا تأخذ السياق في الاعتبار. قد يبدو الملمس حادًا في إطار واحد لكن مختلفًا في التالي، مما يخلق تأثيرًا متلألئًا مشتتًا وغير طبيعي. قد تتغير الوجوه في المظهر بين الإطارات، مع تحول العيون أو ملمس الجلد بطرق تبدو خاطئة.
هذه الأ artifacts أكثر ملاحظة من الجودة المنخفضة الأصلية، مما يجعل التحسين إطارًا بإطار غير منتج. قد يكون للفيديو دقة أعلى، لكن عدم الاتساق الزمني يجعله يبدو أسوأ بشكل عام.
الاختراق الحقيقي: الاتساق الزمني
أدوات تحسين الفيديو الحديثة تحل هذا عن طريق تحليل إطارات متعددة معًا، مما يضمن بقاء التفاصيل مستقرة عبر الوقت. خوارزميات الاتساق الزمني تحلل الإطار الحالي مع عدة إطارات قبل وبعد، مستخدمة معلومات من الإطارات المحيطة للحفاظ على الاستقرار.
يجب أن تبقى التفاصيل مستقرة عبر الوقت، وليس فقط أن تبدو جيدة في صورة ثابتة. هذا هو السبب في أن الأدوات الجادة مثل Topaz Video AI والمنصات السحابية مثل محسّن جودة الفيديو تركز بشدة على التحليل الزمني. عملية التحسين تأخذ في الاعتبار التسلسل بالكامل، وليس فقط الإطارات الفردية.
هذا الوعي الزمني يمنع التوهج، والزحف، وعدم الاستقرار. يبقى الملمس متسقًا، والوجوه مستقرة، والحركة تبدو طبيعية لأن الذكاء الاصطناعي يستخدم معلومات من إطارات متعددة للحفاظ على التماسك. النتيجة هي تحسين يبدو جيدًا في كل من الإطارات الثابتة وأثناء التشغيل.
نماذج الانتشار موضحة
نماذج الانتشار تمثل تقدمًا كبيرًا في تحسين الفيديو بالذكاء الاصطناعي، مما يقدم توليد تفاصيل متفوقًا مقارنة بأنظمة GAN السابقة.
ما هي نماذج الانتشار حقًا
نماذج الانتشار هي نماذج توليدية مدربة للتنبؤ بتفاصيل بصرية معقولة من خلال عملية تحسين متكررة. تعمل عن طريق تعلم عكس عملية إضافة الضوضاء، مما يبني التفاصيل تدريجيًا من مدخلات منخفضة الدقة أو صاخبة.
هذه النماذج قوية للغاية في توليد الملمس، والوجوه، والبنى الدقيقة لأنها مدربة على مجموعات بيانات ضخمة من الصور والفيديو عالية الجودة. عملية التدريب تعلمهم التعرف على الأنماط وإنشاء تفاصيل تطابق المظهر الطبيعي، مما ينتج نتائج تبدو مقنعة للمشاهدين البشر.
Stable Diffusion: نموذج صورة، وليس فيديو أصلي
Stable Diffusion هو نموذج صورة، وليس نموذج فيديو أصلي، مما يخلق تحديات عند تطبيقه على تحسين الفيديو. عند استخدامه للفيديو، عادة ما تُطبق نماذج الانتشار إطارًا بإطار، ثم تُجمع مع التوجيه الزمني لتقليل التوهج.
هذا النهج الهجين يعمل لكنه ليس مثاليًا. الانتشار إطارًا بإطار يمكن أن يخلق عدم اتساق زمني، مما يتطلب معالجة إضافية للحفاظ على الاستقرار عبر الإطارات. التوجيه الزمني يساعد، لكنه حل بديل لنموذج لم يُصمم للفيديو.
أحدث ما توصلت إليه 2026: خطوط الأنابيب الهجينة
الأدوات المتقدمة في 2026 تستخدم خطوط أنابيب هجينة تجمع بين الدقة الفائقة للفيديو الكلاسيكية وتحسين التفاصيل القائم على الانتشار. هذا النهج يتجاوز أنظمة GAN فقط الأقدم، مستفيدًا من نقاط القوة في كل من الطرق الكلاسيكية والتوليدية.
النهج الهجين يعمل عن طريق استخدام الدقة الفائقة الكلاسيكية للتحسين الأساسي، ثم تطبيق نماذج الانتشار لتحسين التفاصيل. هذا ينتج نتائج مستقرة (من الطرق الكلاسيكية) ومفصلة (من نماذج الانتشار)، مما يخلق تحسينًا يبدو طبيعيًا ومقنعًا.
عندما يذهب الذكاء الاصطناعي بعيدًا: مشكلة المظهر "المزيف"
تحسين الذكاء الاصطناعي يمكن أن ينتج أ artifacts تجعل الفيديو يبدو اصطناعيًا، خاصة عندما تكون المعالجة عدوانية جدًا أو عندما تكون المادة المصدر متدهورة جدًا.
أوضاع الفشل الشائعة
الأ artifacts تحدث عندما يسيء الذكاء الاصطناعي تفسير الأنماط، مما يخلق تفاصيل لا تطابق المحتوى. قد تظهر الطوب حيث لا يوجد، أو قد يُولد ملمس القماش بشكل غير صحيح، أو قد تُنشأ أنماط تبدو غير طبيعية.
الجلد الشمعي يحدث عندما يزيل الذكاء الاصطناعي المسام الطبيعية والملمس، مما يخلق مظهرًا بلاستيكيًا ملحوظًا فورًا. يحدث هذا عندما تنعم خوارزميات التحسين بشكل عدواني جدًا، مما يزيل الاختلافات الدقيقة التي تجعل الجلد يبدو حقيقيًا.
الحدة المفرطة تخلق تفاصيل تبدو مرسومة، مع حواف حادة جدًا وملمس يبدو اصطناعيًا. التفاصيل قد تكون تقنيًا "صحيحة" لكنها لا تطابق المظهر الطبيعي، مما يخلق تأثير الوادي الغريب.
الحل الحديث: التحسين المتحكم فيه
الأدوات الاحترافية تعالج هذه المشاكل من خلال قوة التحسين المتحكم فيها والحفاظ على حبيبات الفيلم. التحسين المتحكم فيه يسمح للمستخدمين بتعديل شدة المعالجة، مما يجد التوازن بين التحسين والمظهر الطبيعي.
الحفاظ على حبيبات الفيلم أو إعادة حقنها يحافظ على الملمس الطبيعي الذي قد يُفقد أثناء المعالجة. بعض الأدوات يمكنها تحليل وحفظ الحبيبات الأصلية، أو إضافة حبيبات اصطناعية مرة أخرى بعد التحسين، مما يحافظ على المظهر الطبيعي الذي يتوقعه المشاهدون.
الأدوات الاحترافية تعرض ضوابط الضبط لتجنب المعالجة المفرطة، مما يمنح المستخدمين تحكمًا في معاملات التحسين. هذا يسمح بالضبط الدقيق الذي ينتج نتائج طبيعية بدلاً من تحسين يبدو اصطناعيًا.
معايير العالم الحقيقي: ما يمكن أن تحققه الأدوات المختلفة
فهم ما يمكن أن تحققه الأدوات المختلفة فعليًا يساعد في وضع توقعات واقعية واختيار النهج الصحيح للقطات الخاصة بك.
مصادر منخفضة الجودة: VHS، MiniDV، 480p
المصادر منخفضة الجودة تظهر تحسينًا إدراكيًا كبيرًا عند تحسينها بأدوات الذكاء الاصطناعي الحديثة. أشرطة VHS، ولقطات MiniDV، وفيديوهات 480p يمكن رفعها إلى 1080p أو 4K مع نتائج تبدو أفضل بشكل كبير من الأصل.
النتائج لا تزال منمقة، وليست حديثة بشكل سحري. اللقطات المحسّنة تحافظ على طابع الأصل بينما تبدو أكثر حدة ونظافة بشكل كبير. لا يمكن للذكاء الاصطناعي القضاء تمامًا على قيود المادة المصدر، لكنه يمكن أن يخلق نتائج متفوقة بصريًا وأكثر قابلية للمشاهدة.
هذا يعمل بشكل أفضل عندما تكون المادة المصدر لديها أ artifacts ضغط قليلة وتركيز معقول. اللقطات المتدهورة بشدة مع ضغط شديد أو ضبابية حركة ستنتج نتائج أقل إثارة للإعجاب، لكن حتى في هذه الحالات، يمكن للأدوات الحديثة إنشاء تحسين ملحوظ. عند التعامل مع لقطات ضبابية، فهم نوع الضبابية يساعد في تحديد ما إذا كان التحسين سيكون فعالاً.
مصادر متوسطة الجودة: 1080p الهواتف الذكية، DSLRs
المصادر متوسطة الجودة تحقق جودة إدراكية 4K قريبة من الأصلية عند تحسينها بأدوات احترافية. لقطات الهاتف الذكي الحديثة وفيديو DSLR المسجل بدقة 1080p يمكن رفعه إلى 4K مع نتائج تبدو تقريبًا جيدة مثل لقطات 4K الأصلية.
هذا هو المكان الذي تبرز فيه أدوات مثل Topaz Video AI ومحسّن جودة الفيديو أكثر. المادة المصدر تحتوي على معلومات كافية للتنبؤات الدقيقة بالذكاء الاصطناعي، مما يسمح للأدوات بإنشاء تفاصيل تبدو طبيعية ومقنعة. اللقطات المحسّنة تحافظ على طابع الأصل مع تحقيق دقة أعلى وجودة إدراكية.
المفتاح هو البدء بمادة مصدر لائقة. فيديو 1080p مسجل بمعدل بت عالي سيرفع بشكل أفضل من فيديو 1080p مسجل بمعدل بت منخفض، لأن معدل البت الأعلى يحافظ على المزيد من المعلومات للذكاء الاصطناعي للعمل معها.
المقاييس مقابل الرؤية البشرية: لماذا "يبدو أفضل" مهم
فيديو محسّن بالذكاء الاصطناعي قد يسجل أقل في المقاييس التقنية مثل VMAF بينما يبدو أفضل بشكل كبير للمشاهدين البشر. هذه المفارقة تكشف لماذا الجودة الإدراكية مهمة أكثر من دقة مستوى البكسل.
مفارقة الدقة
فيديو محسّن بالذكاء الاصطناعي قد يسجل أقل في مقاييس مثل VMAF لأن عملية التحسين تخلق تفاصيل لم تكن في الأصل. المقاييس التقنية تقيس الدقة للمصدر، لكن تحسين الذكاء الاصطناعي يخلق عمدًا تفاصيل جديدة، مما يمكن أن يخفض درجات الدقة. مقياس VMAF (Video Multi-method Assessment Fusion) المطور من Netflix يجمع قياسات جودة متعددة للتنبؤ بالإدراك البشري، لكنه يقيس الولاء للمصدر بدلاً من التحسين الإدراكي.
لكن الفيديو المحسّن يبدو أفضل بشكل كبير للمشاهدين البشر، الذين يهتمون أكثر بالوضوح، والوجوه، واستقرار الحركة من دقة مستوى البكسل. هذا يخلق موقفًا حيث المقاييس التقنية تشير إلى جودة أقل، لكن الإدراك البشري يشير إلى جودة أعلى.
لماذا يحدث هذا
الذكاء الاصطناعي يولي الأولوية للجودة الإدراكية، وليس دقة مستوى البكسل. عملية التحسين مصممة لإنشاء نتائج تبدو جيدة للبشر، وليس لمطابقة الأصل بكسلًا بكسل. هذا يعني أن الذكاء الاصطناعي قد يولد تفاصيل تحسن الجودة الإدراكية حتى لو قللت الدقة التقنية.
البشر يهتمون أكثر بالوضوح، والوجوه، واستقرار الحركة من ما إذا كان كل بكسل يطابق الأصل. إذا بدا الوجه أكثر حدة وطبيعية، يدرك المشاهدون جودة أعلى حتى لو لم تطابق النسخة المحسّنة الأصل بكسلًا بكسل. إذا لم تكن متأكدًا مما إذا كانت لقطاتك مناسبة للتحسين، ChatGPT يمكنه المساعدة في تحليل جودة فيديوك والتوصية بالنهج الصحيح.
هذا التمييز مهم لفهم نتائج التحسين. المقاييس التقنية توفر منظورًا واحدًا، لكن الإدراك البشري يوفر آخر، وبالنسبة لتحسين الفيديو، الإدراك البشري هو ما يهم في النهاية.
كيفية معرفة ما إذا كانت أداة تحسين الفيديو جيدة فعليًا
معظم المراجعات تركز على جودة الإخراج لكنها تتجاهل العوامل الحرجة التي تحدد ما إذا كان التحسين يحسن الفيديو فعليًا أو يقدم مشاكل جديدة.
الاختبارات التي تتجاهلها معظم المراجعات
اختبار التوهج الزمني يتحقق مما إذا كان الملمس يتلألأ بين الإطارات. أداة تحسين جيدة تحافظ على ملمس مستقر طوال الفيديو، بينما الأدوات السيئة تخلق توهجًا ملحوظًا فورًا أثناء التشغيل.
اختبار استقرار الوجه يتحقق مما إذا كانت العيون والجلد تبقى متسقة عبر الإطارات. يجب أن تبدو الوجوه مستقرة وطبيعية طوال الفيديو، وليس تغيير المظهر بين الإطارات بطرق تبدو خاطئة.
اختبار سلامة الحركة يضمن عدم التشويه أثناء الحركة السريعة. الفيديو المحسّن يجب أن يحافظ على الحركة الطبيعية، مع تحرك الكائنات بسلاسة دون تشويه أو أ artifacts أثناء الحركة السريعة.
رؤى المستوى الاحترافي
تحليل الإطار المرجعي يكشف كيف يقترض الذكاء الاصطناعي التفاصيل من الإطارات الحادة القريبة. الأدوات المتقدمة تحلل إطارات متعددة للعثور على أشد نسخة من كل عنصر، ثم تستخدم تلك المعلومات لتحسين الإطارات الأخرى. هذا يخلق تحسينًا أكثر دقة من معالجة كل إطار بشكل مستقل.
تجنب المعالجة المفرطة يعني أن التحسين الخفيف يتفوق على إعادة البناء العدوانية. أفضل النتائج تأتي من التحسين المعتدل الذي يحسن الجودة دون تقديم أ artifacts. المعالجة العدوانية قد تخلق المزيد من التفاصيل، لكنها غالبًا تبدو اصطناعية وتقلل الجودة الإجمالية.
فحص واقع الأجهزة: الأدوات المحلية تتطلب بطاقات رسوميات قوية، بينما المنصات السحابية تقضي على هذا الحاجز تمامًا. برامج سطح المكتب مثل Topaz Video AI تحتاج بطاقات رسوميات NVIDIA RTX أو Apple Silicon لسرعات معالجة عملية. الحلول السحابية مثل محسّن جودة الفيديو تقضي على متطلبات الأجهزة، مما يجعل التحسين الاحترافي متاحًا بغض النظر عن الإعداد المحلي. إذا كنت تعمل مع ChatGPT لتوجيه سير عمل التحسين الخاص بك، يمكنه مساعدتك في الاختيار بين النهج المحلي والسحابي بناءً على أجهزتك.
الحكم النهائي: هل يمكن للذكاء الاصطناعي حقًا تحسين جودة الفيديو؟
الإجابة هي نعم، لكن مع تحذيرات مهمة تشرح متى يعمل التحسين ومتى لا يعمل.
الذكاء الاصطناعي لا يستعيد الواقع المفقود
الذكاء الاصطناعي لا يستعيد الواقع المفقود. بدلاً من ذلك، يعيد بناء تفاصيل معقولة. إذا تم تسجيل فيديو بدقة 480p، فلا توجد نسخة 4K مخفية في البيانات. الكاميرا لم تلتقط تلك التفاصيل أبدًا. تحسين الذكاء الاصطناعي يخلق تفاصيل معقولة بناءً على بيانات التدريب، وليس معلومات مستعادة.
هذا التمييز مهم لفهم ما يمكن أن يحققه التحسين. الفيديو المحسّن يمثل ما يعتقد الذكاء الاصطناعي أنه يجب أن يكون موجودًا، وليس بالضرورة ما تم التقاطه فعليًا. هذا إعادة بناء، وليس استعادة.
عند القيام بذلك بشكل صحيح، النتائج مستقرة وطبيعية ومتفوقة بصريًا
عند القيام بذلك بشكل صحيح، ينتج تحسين الذكاء الاصطناعي نتائج مستقرة وطبيعية ومتفوقة بصريًا. الأدوات الحديثة مع الاتساق الزمني تخلق تحسينًا يبدو جيدًا في كل من الإطارات الثابتة وأثناء التشغيل، مما يحافظ على المظهر الطبيعي طوال الوقت.
المفتاح هو استخدام الأداة الصحيحة لمادة المصدر الخاصة بك وتطبيق قوة تحسين مناسبة. الأدوات الاحترافية مع التحليل الزمني المناسب تنتج نتائج تبدو مقنعة وطبيعية، مما يتجنب الأ artifacts وعدم الاستقرار التي تؤثر على المعالجة إطارًا بإطار.
تحسين الفيديو بالذكاء الاصطناعي ليس عن الحقيقة: إنه عن الوضوح المقنع
تحسين الفيديو بالذكاء الاصطناعي ليس عن الحقيقة. إنه عن الوضوح المقنع. الهدف ليس استعادة المعلومات المفقودة بل إنشاء نتائج تبدو أفضل للمشاهدين البشر. إذا بدا الفيديو المحسّن أكثر حدة ونظافة وطبيعية، فقد حقق هدفه، حتى لو كانت التفاصيل تقنيًا "مهلوسة".
هذا المنظور يساعد في وضع توقعات واقعية. تحسين الذكاء الاصطناعي يخلق نتائج معقولة ومتفوقة بصريًا، وليس إعادة بناء مثالية للمعلومات المفقودة. التكنولوجيا تعمل بشكل أفضل عندما تحتوي المادة المصدر على معلومات كافية للتعرف الدقيق على الأنماط، مما يسمح للذكاء الاصطناعي بإنشاء تفاصيل تبدو طبيعية ومقنعة.